Il primo mese del 2023 ha portato duri licenziamenti da parte dei colossi tecnologici(nuova finestra), un potenziale divieto di TikTok negli Stati Uniti(nuova finestra) e un altro attacco informatico a Twitter. Ma lo sviluppo più significativo di questo nuovo anno deve essere l’ascesa di ChatGPT(nuova finestra).
Il chatbot è in grado di produrre testi sorprendentemente simili a quelli umani e, a seconda del comando, persino generare risposte creative che sembrano non poter provenire da un computer:
Il ritmo del progresso è sbalorditivo. E, se la tecnologia passata è un modello, questo si accelererà solo. L’attuale generazione di chatbot ha già superato il test di Turing, rendendo molto probabile che i chatbot basati sull’IA saranno presto applicati a tutti i tipi di lavori, compiti e dispositivi nel prossimo futuro. È solo questione di tempo prima che interagire con l’IA diventi una parte regolare della nostra routine quotidiana. Questa proliferazione accelererà solo ulteriormente lo sviluppo dell’IA.
Queste sono tutte ottime notizie! L’IA è uno strumento potente che potrebbe portare a tutti i tipi di nuovi sviluppi e scoperte. Tuttavia, come per ogni strumento, dobbiamo assicurarci che venga utilizzato e sviluppato in modo responsabile. In Proton, abbiamo notato che, nonostante la grande pubblicità intorno a ChatGPT, c’è stata poca analisi delle questioni di privacy che l’IA solleva.
Spiegheremo come l’IA, come ChatGPT, necessita di dati per svilupparsi e come l’IA in futuro potrebbe presentare nuove sfide alla nostra privacy.
Abbiamo persino intervistato ChatGPT sul futuro della privacy, e ha fornito alcune buone risposte.
Puoi vedere più della nostra conversazione con ChatGPT(nuova finestra) nei prossimi giorni.
Addestrare l’IA richiede dati – molti dati
Enormi quantità di dati sono necessarie per addestrare e migliorare la maggior parte dei modelli di IA. Più dati vengono inseriti nell’IA, meglio può rilevare schemi, anticipare cosa accadrà dopo e creare qualcosa di completamente nuovo. Il processo è più o meno questo:
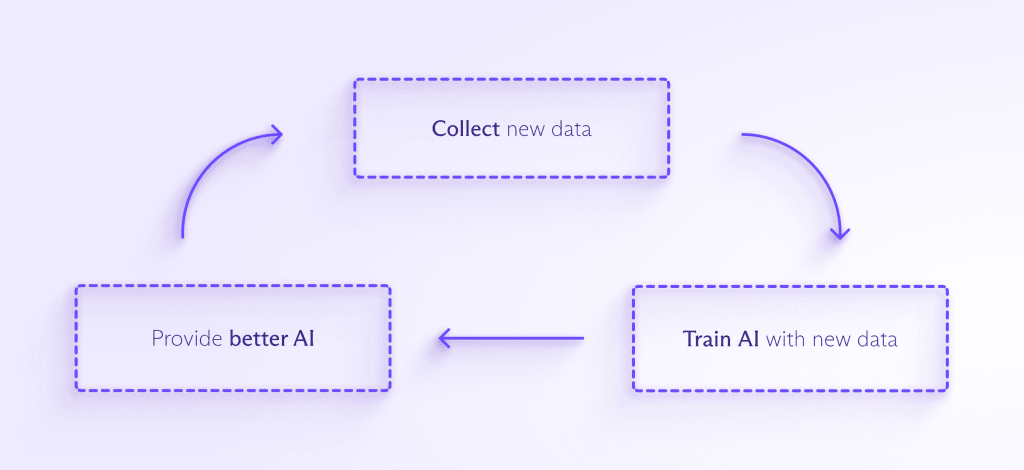
Man mano che l’IA viene integrata in più prodotti destinati ai consumatori, ci sarà la pressione per raccogliere ancora più dati per addestrarla. E man mano che le persone interagiscono sempre più spesso con l’IA, le aziende vorranno probabilmente raccogliere i tuoi dati personali per aiutare il tuo assistente IA a capire come dovrebbe rispondere a te, in particolare.
Questo porta a tutti i tipi di problemi. Un’IA addestrata su dati imparerà solo a gestire situazioni sollevate dal set di dati che ha visto. Se i tuoi dati non sono rappresentativi, l’IA replicherà quel pregiudizio nel suo processo decisionale, che è esattamente ciò che è successo ad Amazon quando il suo bot di reclutamento IA penalizzava le candidate donne(nuova finestra) dopo essere stato addestrato su curriculum in un dataset dominato da uomini.
Allo stesso modo, se l’IA incontra una situazione che non ha mai visto nei suoi dati di addestramento, potrebbe non sapere cosa fare. Questo è stato il caso con un veicolo autonomo di Uber che ha ucciso un pedone(nuova finestra) che non è riuscito a identificare poiché la persona si trovava fuori da un attraversamento pedonale.
E prima che un’intelligenza artificiale possa essere addestrata sui dati, questi devono essere puliti, il che significa formattarli correttamente ed eliminare contenuti razzisti, sessisti, violenti o discutibili. Come la moderazione dei contenuti per aziende come Meta, questo compito è tipicamente estenuante, mal pagato e nascosto al pubblico. È di recente emerso che OpenAI si è affidata a centinaia di persone in Kenya(nuova finestra) per pulire i dati per GPT-3, che sono rimaste traumatizzate dal lavoro.
Per evitare questi tipi di pregiudizi e punti ciechi, le aziende dovranno raccogliere ancora più dati di quanto faccia attualmente il Big Tech per vendere pubblicità personalizzate. Potresti non saperlo, ma questi sforzi sono già iniziati.
Come esempio della scala di cui stiamo parlando, l’intera Wikipedia in inglese, che comprende circa 6 milioni di articoli, ha costituito solo lo 0,6% dei dati di allenamento per GPT-3(nuova finestra), di cui ChatGPT è una variante.
Un esempio più noto è Clearview AI(nuova finestra), che ha raccolto le immagini delle persone dal web e le ha utilizzate per addestrare il suo AI di sorveglianza facciale senza il permesso delle persone. Il suo database contiene circa 20 miliardi di immagini.
Clearview ha ricevuto ogni tipo di cause legali, multe e ordini di cessazione e desistenza per il suo palese disprezzo della privacy delle persone. Tuttavia, è riuscita a evitare di pagare molte multe e ha resistito all’eliminazione dei dati nonostante gli ordini dei regolatori(nuova finestra), potenzialmente aprendo la strada che altri sviluppatori di AI senza scrupoli potrebbero seguire.
Un’altra preoccupazione è che l’onnipresenza dell’AI potrebbe rendere quasi impossibile evitare tale raccolta di dati.
L’AI esaminerà ora il tuo caso
Attualmente, siamo preoccupati per la quantità di dati che il Big Tech raccoglie da noi mentre navighiamo online o tramite dispositivi smart connessi a Internet. Tuttavia, il numero di dispositivi smart e la quantità complessiva di raccolta dati aumenteranno vertiginosamente man mano che l’AI e i chatbot miglioreranno. E l’AI inizierà a prendere il sopravvento su parti della nostra vita già dominate dagli algoritmi, rendendo impossibile sfuggire.
Attualmente, a seconda di dove vivi, un algoritmo potrebbe decidere se ricevi la cauzione(nuova finestra) prima del tuo processo, se sei idoneo per un mutuo(nuova finestra) e quanto paghi per l’assicurazione sanitaria(nuova finestra). L’AI assumerà questi compiti essenziali e probabilmente si espanderà in ancor più settori. Sembra esserci una ricerca senza fine dell’uso dell’AI per prevedere il crimine(nuova finestra). E sono già stati condotti esperimenti utilizzando GPT-3 come chatbot medico(nuova finestra) (con alcuni risultati disastrosi).
Man mano che l’AI verrà applicata a nuove funzioni, sarà esposta a informazioni sempre più sensibili e diventerà sempre più difficile per le persone evitare di condividere i propri dati con l’AI. Inoltre, una volta raccolti i dati, è molto facile che vengano riproposti o utilizzati per qualcosa a cui le persone non hanno mai dato il consenso.
Non sappiamo come sarà l’AI in futuro
Nel 1965, i computer occupavano intere stanze(nuova finestra). Quello fu l’anno in cui Gordon Moore formulò quella che sarebbe stata chiamata la Legge di Moore(nuova finestra), secondo la quale il numero di transistor che possono essere inseriti su un circuito integrato raddoppia ogni due anni. La sua previsione si è dimostrata notevolmente accurata per oltre 40 anni e solo recentemente ha iniziato a non verificarsi più. Ma nemmeno lui avrebbe potuto prevedere quanto avanzati sono i nostri computer attuali.
Molto probabilmente, guarderemo indietro a ChatGPT come guardiamo a un computer degli anni ’60 e ci meraviglieremo di come chiunque sia riuscito a fare qualcosa con esso. Il semplice fatto è che siamo all’inizio di un viaggio tecnologico epocale e non abbiamo idea di dove ci porterà.
Attualmente, le persone sono preoccupate di come le piattaforme del Big Tech possano influenzare sottilmente il nostro processo decisionale e creare bolle di filtro dalle quali è impossibile sfuggire. Tuttavia, queste potrebbero sembrare strumenti rudimentali rispetto a un motore di ricerca alimentato da AI o a un nuovo servizio. Inoltre, l’AI potrebbe diventare così brava nel riconoscimento di schemi da sviluppare la capacità di de-anonimizzare i dati o abbinare identità attraverso dataset disparati. Tutto ciò può sembrare speculativo, ma è semplicemente perché non abbiamo idea di quali siano i limiti massimi delle capacità dell’AI.
Cosa possiamo fare per preservare la privacy in un futuro alimentato dall’AI?
La buona notizia è che ci sono cose che possiamo fare fin da ora per assicurarci che l’AI venga addestrata in modo responsabile utilizzando dati anonimizzati. Pianifichiamo di scrivere un altro articolo in futuro sui metodi che le aziende possono utilizzare per addestrare l’AI su dataset proteggendo al contempo la privacy delle persone.
Se ti preoccupa la tua privacy, non è mai troppo presto per iniziare a proteggere le tue informazioni. Se cripti i tuoi dati (con servizi come Proton Mail o Proton Drive), li rimuoverai dal controllo di Big Tech o da database pubblici, impedendo che vengano utilizzati per tracciarti o addestrare l’AI.
Puoi anche utilizzare siti come Have I Been Trained(nuova finestra) per vedere se una delle tue immagini è già stata utilizzata per addestrare l’AI. Purtroppo, anche se scopri che una delle tue immagini è stata utilizzata senza il tuo permesso, non è sempre facile capire come fare per rimuoverla(nuova finestra).
Per quanto riguarda i responsabili delle politiche, possono iniziare a delineare quadri normativi per l’uso dell’AI che consacrino il diritto alla privacy. Ma dobbiamo agire ora. L’AI si svilupperà probabilmente a un ritmo esponenziale, il che significa che dobbiamo rispondere a queste domande ora prima che sia troppo tardi.
La prima cosa che si può fare è che ogni paese approvi una legge sulla privacy dei dati che limiti i tipi di dati personali che possono essere raccolti e per cosa quei dati possono essere legalmente utilizzati. Questo renderebbe più facile reprimere aziende come Clearview AI.
Guardando avanti, i responsabili delle politiche possono richiedere che le aziende di AI forniscano trasparenza su come funzionano i loro algoritmi e modelli di AI, o almeno sui dataset che stanno utilizzando per addestrare i loro sistemi. Questo aiuterà anche queste aziende a evitare di perpetuare i pregiudizi e le lacune nell’AI di cui abbiamo discusso in precedenza.
I responsabili delle politiche dovrebbero anche obbligare le aziende di AI a sottoporre i loro modelli a audit regolari e avere ufficiali indipendenti per la privacy dei dati per assicurarsi che i dati vengano utilizzati in modo responsabile.
Questo è un momento entusiasmante nella storia dell’umanità. L’AI è una frontiera inesplorata, ma prima di avventurarci, dobbiamo assicurarci di aver tutelato i nostri diritti umani fondamentali.
Aggiornamento 30 gennaio 2023: Abbiamo rimosso un riferimento riguardo ai lavoratori che hanno pulito i dati per ChatGPT essendo mal pagati dopo che sono state rilasciate le cifre dei pagamenti.






