Der erste Monat des Jahres 2023 brachte harte Entlassungen der Big Tech(neues Fenster), ein mögliches Verbot von TikTok in den USA(neues Fenster) und einen weiteren Twitter-Datenleck. Aber die bedeutendste Entwicklung dieses neuen Jahres ist sicherlich der Aufstieg von ChatGPT(neues Fenster).
Der Chatbot kann bemerkenswert menschlich klingenden Text produzieren und, je nach Aufforderung, sogar kreative Antworten generieren, die so klingen, als könnten sie unmöglich von einem Computer stammen:
Das Tempo des Fortschritts ist atemberaubend. Und wenn man vergangene Technologien als Modell nimmt, wird es nur noch schneller vorangehen. Die aktuelle Generation von Chatbots hat den Turing-Test bereits durchbrochen, sodass es sehr wahrscheinlich ist, dass KI-gesteuerte Chatbots bald für alle möglichen Jobs, Aufgaben und Geräte in naher Zukunft eingesetzt werden. Es ist nur eine Frage der Zeit, bis die Interaktion mit KI ein regelmäßiger Teil unseres Alltags wird. Diese Verbreitung wird die Entwicklung der KI nur weiter beschleunigen.
Das ist alles eine gute Nachricht! KI ist ein mächtiges Werkzeug, das zu allerlei neuen Entwicklungen und Durchbrüchen führen könnte. Allerdings müssen wir, wie bei jedem Werkzeug, sicherstellen, dass es verantwortungsbewusst genutzt und entwickelt wird. Bei Proton haben wir bemerkt, dass es trotz der ganzen Publicity um ChatGPT wenig Untersuchung der Privatsphäre-Fragen gibt, die KI aufwirft.
Wir werden erklären, wie KI, wie ChatGPT, Daten für die Entwicklung benötigt und wie KI in der Zukunft neue Herausforderungen für unsere Privatsphäre darstellen könnte.
Wir haben sogar ChatGPT über die Zukunft der Privatsphäre interviewt und es hat einige gute Antworten geliefert.
Du kannst mehr von unserem Gespräch mit ChatGPT(neues Fenster) in den nächsten Tagen sehen.
KI-Training erfordert Daten – und zwar viele Daten
Massive Datenmengen sind erforderlich, um die meisten KI-Modelle zu trainieren und zu verbessern. Je mehr Daten der KI zugeführt werden, desto besser kann sie Muster erkennen, voraussehen, was als Nächstes kommt, und etwas völlig Neues erschaffen. Der Prozess sieht ungefähr so aus:
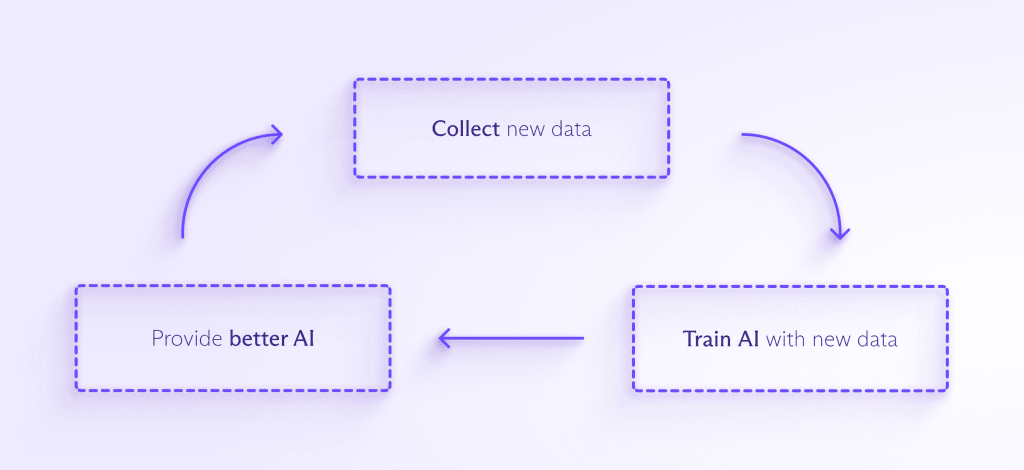
Da KI in immer mehr kundenorientierte Produkte integriert wird, wird es Druck geben, noch mehr Daten zu sammeln, um sie zu trainieren. Und je öfter Menschen mit KI interagieren, desto eher werden Unternehmen wahrscheinlich deine persönlichen Daten sammeln wollen, um deinem KI-Assistenten zu helfen zu verstehen, wie er speziell auf dich reagieren soll.
Das führt zu allerlei Problemen. Eine an Daten trainierte KI wird nur lernen, wie sie mit Situationen umgehen kann, die durch den Datensatz vorgegeben sind, den sie gesehen hat. Wenn deine Daten nicht repräsentativ sind, wird die KI diese Voreingenommenheit in ihrer Entscheidungsfindung replizieren, was genau das ist, was Amazon erlebte, als sein KI-Rekrutierungsbot weibliche Kandidaten benachteiligte(neues Fenster), nachdem er mit Lebensläufen aus einem von Männern dominierten Datensatz trainiert wurde.
Ähnlich, wenn KI auf eine Situation trifft, die sie in ihren Trainingsdaten nie gesehen hat, weiß sie möglicherweise nicht, was zu tun ist. Das war der Fall bei einem selbstfahrenden Uber-Fahrzeug, das einen Fußgänger tötete(neues Fenster), den es nicht identifizieren konnte, da die Person außerhalb eines Zebrastreifens war.
Bevor ein KI-System mit Daten trainiert werden kann, müssen diese Daten bereinigt werden, was bedeutet, sie richtig zu formatieren und rassistischen, sexistischen, gewalttätigen oder anstößigen Inhalt zu löschen. Ähnlich wie die Inhaltsmoderation bei Unternehmen wie Meta ist diese Aufgabe in der Regel mühsam, schlecht bezahlt und vor der Öffentlichkeit verborgen. Kürzlich wurde bekannt, dass OpenAI sich auf Hunderte von Menschen in Kenia(neues Fenster) verlassen hat, um die Daten für GPT-3 zu bereinigen, was bei den Arbeitern zu Traumata führte.
Damit KI solche Voreingenommenheiten und blinde Flecken vermeiden kann, müssen Unternehmen noch mehr Daten sammeln, als Big Tech derzeit tut, um personalisierte Werbung zu verkaufen. Vielleicht weißt du es noch nicht, aber diese Bemühungen haben bereits begonnen.
Als Beispiel für den Umfang, über den wir sprechen, machte die gesamte englischsprachige Wikipedia, die etwa 6 Millionen Artikel umfasst, nur 0,6% der Trainingsdaten für GPT-3(neues Fenster) aus, von dem ChatGPT eine Variante ist.
Ein berüchtigteres Beispiel ist Clearview AI(neues Fenster), das Bilder von Menschen aus dem Internet gesammelt und ohne deren Erlaubnis verwendet hat, um seine Gesichtserkennungs-KI zu trainieren. Seine Datenbank enthält etwa 20 Milliarden Bilder.
Clearview hat alle Arten von Klagen, Bußgeldern und Unterlassungsaufforderungen wegen seiner eklatanten Missachtung der Privatsphäre der Menschen erhalten. Dennoch konnte es viele Bußgelder vermeiden und hat trotz behördlicher Anordnungen die Löschung von Daten verweigert(neues Fenster), was möglicherweise einen Weg ebnet, den andere skrupellose KI-Entwickler folgen könnten.
Ein weiteres Bedenken ist, dass die Allgegenwärtigkeit von KI eine solche Datensammlung nahezu unvermeidlich machen könnte.
Die KI wird jetzt deinen Fall anhören
Derzeit sind wir besorgt über die Menge an Daten, die Big Tech von uns sammelt, während wir online browsen oder über internetverbundene Smart-Geräte. Allerdings wird die Anzahl der Smart-Geräte und das Ausmaß der Datensammlung in die Höhe schnellen, wenn sich KI und Chatbots weiterentwickeln. Und KI wird anfangen, Teile unseres Lebens zu übernehmen, die bereits von Algorithmen dominiert werden, was es unmöglich macht, ihnen zu entkommen.
Derzeit kann je nach Wohnort ein Algorithmus entscheiden, ob du eine Kaution vor deiner Verhandlung erhältst(neues Fenster), ob du für einen Wohnungskredit qualifiziert bist(neues Fenster) und wie viel du für die Krankenversicherung bezahlst(neues Fenster). KI wird diese wesentlichen Aufgaben übernehmen und wahrscheinlich in noch mehr Bereiche expandieren. Es scheint ein unendliches Bestreben zu geben, KI zur Verbrechensvorhersage zu nutzen(neues Fenster). Und es wurden bereits Experimente durchgeführt, bei denen GPT-3 als medizinischer Chatbot(neues Fenster) eingesetzt wurde (mit teils katastrophalen Ergebnissen).
Wenn KI auf neue Funktionen angewendet wird, wird sie immer mehr sensible Informationen erhalten und es wird für Menschen immer schwieriger, die Weitergabe ihrer Informationen an KI zu vermeiden. Außerdem ist es, sobald Daten gesammelt wurden, sehr einfach, diese für etwas zu verwenden, zu dem die Menschen nie zugestimmt haben.
Wir wissen nicht, wie KI in der Zukunft aussehen wird
1965 nahmen Computer ganze Räume ein(neues Fenster). In demselben Jahr formulierte Gordon Moore das, was später als Moores Gesetz(neues Fenster) bekannt wurde, das besagt, dass sich die Anzahl der Transistoren, die auf einen integrierten Schaltkreis passen, alle zwei Jahre verdoppelt. Seine Vorhersage erwies sich über 40 Jahre als bemerkenswert genau und begann erst kürzlich, an Gültigkeit zu verlieren. Aber selbst er hätte nicht vorhersagen können, wie fortschrittlich unsere heutigen Computer sind.
Sehr wahrscheinlich werden wir auf ChatGPT zurückblicken, so wie wir heute auf einen Computer aus den 60er Jahren blicken und uns wundern, wie jemand damit überhaupt etwas erledigen konnte. Die einfache Tatsache ist, dass wir am Anfang einer gewaltigen technologischen Reise stehen und keine Ahnung haben, wohin sie uns führen wird.
Derzeit sind die Menschen besorgt darüber, wie Big-Tech-Plattformen unsere Entscheidungsfindung subtil beeinflussen und Filterblasen erschaffen können, denen wir nicht entkommen können. Diese könnten jedoch im Vergleich zu einer von KI betriebenen Suchmaschine oder einem neuen Dienst als grobe Werkzeuge erscheinen. Außerdem könnte KI so gut in der Mustererkennung werden, dass sie die Fähigkeit entwickelt, Daten zu deanonymisieren oder Identitäten über verschiedene Datensätze hinweg zu verknüpfen. Das mag alles spekulativ klingen, aber das liegt einfach daran, dass wir keine Ahnung von den oberen Grenzen der KI-Fähigkeiten haben.
Was können wir tun, um die Privatsphäre in einer von KI geprägten Zukunft zu bewahren?
Die gute Nachricht ist, dass wir bereits jetzt Maßnahmen ergreifen können, um sicherzustellen, dass KI verantwortungsbewusst mit anonymisierten Daten trainiert wird. Wir planen, in Zukunft einen weiteren Artikel über Methoden zu schreiben, mit denen Unternehmen KI unter Wahrung der Privatsphäre der Menschen mit Datensätzen trainieren können.
Wenn du besorgt um deine Privatsphäre bist, ist es nie zu früh, damit anzufangen, deine Informationen zu schützen. Wenn du deine Daten verschlüsselst (mit Diensten wie Proton Mail oder Proton Drive), wirst du sie aus Big Tech oder öffentlichen Datenbanken entfernen und verhindern, dass sie verwendet werden, um dich zu verfolgen oder KI zu trainieren.
Du kannst auch Websites wie Have I Been Trained(neues Fenster) nutzen, um zu überprüfen, ob eines deiner Bilder bereits zum Trainieren von KI verwendet wurde. Leider ist es, selbst wenn du entdeckst, dass eines deiner Bilder ohne deine Erlaubnis verwendet wurde, nicht immer einfach herauszufinden, wie du es entfernen lassen kannst(neues Fenster).
Was die politischen Entscheidungsträger angeht, so können sie beginnen, Rahmenbedingungen für die KI-Nutzung zu schaffen, die das Recht auf Privatsphäre verankern. Aber wir müssen jetzt handeln. KI wird sich wahrscheinlich exponentiell entwickeln, was bedeutet, dass wir diese Fragen jetzt beantworten müssen, bevor es zu spät ist.
Das Erste, was getan werden kann, ist, dass jedes Land ein Datenschutzgesetz verabschiedet, das festlegt, welche Arten von persönlichen Daten gesammelt werden dürfen und wofür diese Daten rechtlich verwendet werden dürfen. Das würde es erleichtern, gegen Unternehmen wie Clearview AI vorzugehen.
In der Zukunft können politische Entscheidungsträger fordern, dass KI-Unternehmen Transparenz darüber schaffen, wie ihre Algorithmen und KI-Modelle funktionieren, oder zumindest über die Datensätze, die sie zum Trainieren ihrer Systeme verwenden. Das wird diesen Unternehmen auch helfen, die Vorurteile und blinden Flecken in KI zu vermeiden, über die wir zuvor gesprochen haben.
Politische Entscheidungsträger sollten außerdem KI-Unternehmen dazu verpflichten, ihre Modelle regelmäßigen Audits zu unterziehen und unabhängige Datenschutzbeauftragte zu haben, um sicherzustellen, dass Daten verantwortungsvoll genutzt werden.
Dies ist ein aufregender Moment in der Menschheitsgeschichte. KI ist eine unerforschte Grenze, aber bevor wir uns hinauswagen, müssen wir sicherstellen, dass unsere grundlegenden Menschenrechte gesichert sind.
Aktualisierung 30. Januar 2023: Wir haben eine Referenz auf die schlecht bezahlten Arbeiter, die Daten für ChatGPT bereinigt haben, entfernt, nachdem die Zahlungsdaten veröffentlicht wurden.






