
A large language model (LLM) is a computer program that can analyze text inputs and generate responses based on patterns in language. It discovers these patterns on its own using machine learning techniques that have been greatly improved over the last decade. We’ve leveraged these improvements to launch a private AI assistant(nouvelle fenêtre) called Lumo, which solves some of the privacy risks of AI as currently implemented.
This article dives deeply into how LLMs work and how they can be useful. Specifically we’ll cover:
- What are large language models
- How large language models work
- Benefits of large language models
- Privacy risks of mainstream LLMs
- The future of AI and privacy
What are large language models?
A large language model (LLM) is an artificial intelligence system trained to understand and generate human-like text. These models are built using deep learning techniques and trained on massive datasets that include books, articles, websites, and other written content. By analyzing patterns in language, LLMs can predict the next word in a sentence, generate coherent responses, and even engage in complex conversations.
Some popular LLMs include ChatGPT (developed by OpenAI), Claude (Anthropic), Gemini (Google), Llama (Meta), and Mistral (Mistral AI).
It’s important to note that a large language model is not the same thing as the application that runs it. For example, Google integrates Gemini into many of its apps, including Search, YouTube, and its business suite, Workspace. In fact, some LLMs are open source, so any developer can use them in their apps. The LLM is an engine that can power many apps.
How do large language models work?
Large language models generate text by recognizing patterns in massive amounts of written material. (This is why LLMs are known as generative AI, or GenAI.) They do not “think” or “understand” the way humans do, but they are exceptionally good at predicting what words are most likely to come next in a sentence based on what they have seen before.
Let’s take a look at how LLMs work in more detail, starting with how they’re trained and then looking at how they generate new content.
Data collection, training, and fine-tuning
Before an LLM can generate responses, it must first be trained on enormous amounts of text from books, articles, websites, and other sources. This helps the model learn how language works, from basic grammar to more complex ideas like tone and context.
Here are the basic steps of how developers go from a mountain of training data to a finely tuned LLM:
- Converting text to numbers: Large language models operate through numerical computations rather than human-like word processing. They begin by breaking text into smaller pieces called tokens — typically chunks of 3-4 characters — and convert these tokens into numerical values known as embeddings. This numerical representation enables mathematical analysis of language, where the model can identify patterns and connections between different tokens based on their embedding values. The embedding system captures meaningful relationships between words — for example, in the numerical space, “king” sits close to “queen,” “man” relates closely to “king,” and “woman” relates closely to “queen”.
- Processing billions (or trillions) of examples: Through exposure to vast amounts of text data, the model’s comprehension grows increasingly sophisticated. As it processes billions or trillions of examples, it becomes more adept at understanding nuance and context. Take the question “Who were The Carpenters?” — the model learns to recognize that this likely refers to the famous musical group, rather than the occupation or people with that last name.
- Fine-tuning with help from humans: Raw pattern recognition alone isn’t enough to create helpful AI assistants. Models must undergo additional training to align their outputs with human preferences. Traditionally, this was done through Reinforcement Learning from Human Feedback (RLHF), where human raters evaluate the model’s responses across various scenarios. More recently, Direct Preference Optimization (DPO) has emerged as a simpler alternative — achieving similar results by directly training models to prefer better responses over worse ones, without the complexity of reinforcement learning. Through these alignment techniques, models become more reliable, reducing harmful outputs and providing more nuanced, contextually appropriate responses.
The landscape of large language models was revolutionized by Google’s 2017 paper “Attention is all you need(nouvelle fenêtre),” which introduced the transformer architecture. While previous models examined text sequentially — word by word — transformers can process large chunks of text simultaneously. Their key innovation is the ability to weigh the significance of different words in context, determining how much each word matters to understanding the text’s meaning.
This combination of numerical representation, transformer architecture(nouvelle fenêtre), extensive training, and preference learning creates a system that can understand and generate human-like text with remarkable accuracy. While the underlying mechanics involve mathematical computations and token manipulation, the end result is a model that can engage with language in increasingly sophisticated ways — from answering questions and writing code to engaging in complex reasoning tasks. However, it’s important to remember that despite these capabilities, LLMs are pattern recognition systems at their core, processing language through mathematical relationships rather than human-like understanding.
How do LLMs generate text?
One of the defining features of LLMs is that their outputs are probabilistic. That means they build sentences based on likelihood of a word or phrase following another in a given language context.
For example, in the diagram below, you can see how an LLM draws inferences from raw training data to generate outputs that make the most sense in a given context.
On the left is the raw training data. In the center is the model, representing the LLM and the particular set of parameters (or rules) by which tokens (words) are weighted and assembled. On the right is a demonstration of how a sentence might be constructed.
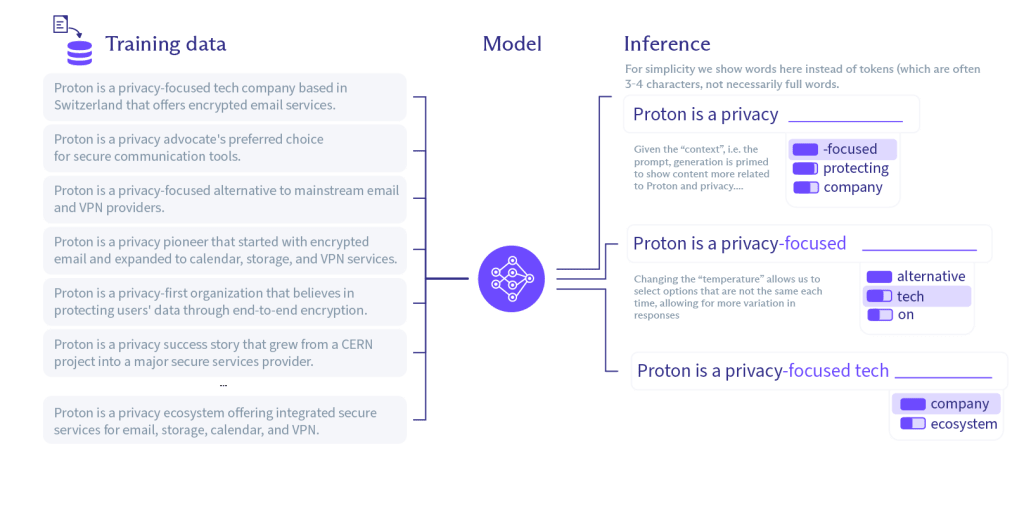
As you can see, there is no single “correct” response but instead a range of possible outputs. An LLM can increase the diversity of possible outputs by increasing the “temperature”. A temperature set to 0 will produce unvarying, deterministic responses; setting the temperature to 1 will produce a broad range of potentially off-track outputs. So most LLMs pick a temperature somewhere in the middle, resulting in different responses to the same query.
Model usage
Once trained, models can be put to work in various applications, from chatbots and search engines to writing assistants and coding tools. Here are a few kinds of software apps that are already using LLMs:
- Productivity and collaboration tools: LLMs can enhance word processors, note-taking apps, project management platforms, and team collaboration software. For example, they might provide writing suggestions, automate project updates, or generate meeting summaries. Proton is already using LLMs to increase productivity for Proton Mail users with our Scribe writing assistant.
- Customer-facing business software: Customer relationship management (CRM) tools, help desk platforms, and e-commerce platforms can use LLMs to suggest personalized follow-ups, draft marketing copy, or generate answers to customer inquiries.
- Coding platforms: Integrated development environments (IDEs), code documentation generators, and cloud management dashboards can incorporate LLMs to assist with code snippets, debug software, and provide simple explanations of a complicated codebase.
- Educational platforms: Online learning systems, language training apps, and workplace training platforms can integrate LLMs to deliver conversational tutoring, produce custom quizzes or exercises, and give clearer explanations of challenging concepts.
- Financial and administrative applications: Budgeting tools, accounting software, and financial planning apps can leverage LLMs to explain financial reports, summarize market patterns, and provide financial advice.
In most cases, these apps are running the LLMs on centralized servers operated by the company that built them (like the ChatGPT apps). An LLM can also be downloaded and run locally on your computer at home, but this is less common because most LLMs require significant computing power. This is an important point because the privacy and security risks of LLMs, which we’ll talk about later, come down to who controls the model and where your data is processed.
What are the benefits of large language models?
LLMs are unique among artificial intelligence tools because of their versatility and accessibility. They’re a general-purpose technology, unlike other sorts of AI used in, say, logistics(nouvelle fenêtre) or playing Go(nouvelle fenêtre). Anyone who can type (or speak(nouvelle fenêtre)) can use an LLM.
Here are three ways LLMs are changing the tech landscape:
- Your personal helper: AI chatbots are essentially personal assistants that can can handle everything from writing emails to planning a vacation. A journalist can quickly summarize lengthy reports. A student can ask an LLM to explain a complex academic paper in simpler terms. We created Lumo(nouvelle fenêtre) to offer you a private version of these capabilities. While other AI assistants collect your personal data, with Lumo, all your conversations are completely confidential.
- Boost business productivity: LLMs offer massive benefits in the workplace. Software developers can write and debug code more efficiently. AI chatbots can handle routine customer service requests almost instantly. Lawyers can quickly scan contracts for relevant information, and financial analysts can generate insights from dense data.
- Break down barriers: For people who are deaf or hard of hearing, voice mode LLMs can convert speech to text in real time. Language barriers are similarly removed. Some LLMs can also process and describe visual information, which is an particular advantage to people who are vision-impaired.
What are the privacy risks of mainstream LLMs?
LLMs are not inherently risky. But most mainstream LLMs are developed by Big Tech companies whose business models are based on collecting and monetizing information about you.
Let’s look at the main concerns about data privacy, security, and control over personal information.
- Personal data collection — Companies like OpenAI, Google, and Microsoft, collect and store user interactions. For an AI chat app, this is particularly troubling because many conversations with LLMs contain sensitive personal and business information. In general, your data is not private, and employees could gain access to your conversations.
- Targeted advertising — Some AI companies have explored the idea of selling targeted ads(nouvelle fenêtre). AI represents a major potential revenue stream for companies whose business model relies on monetizing your interests and behaviors.
- Training on user data — In many cases, your conversations are used to train the LLM(nouvelle fenêtre). This is a privacy risk because your data could become an output in someone else’s conversation with the LLM. This sort of data breach is one reason many companies have banned the use of chatbots with sensitive business data. The diagram below shows how training data can find their way into outputs:
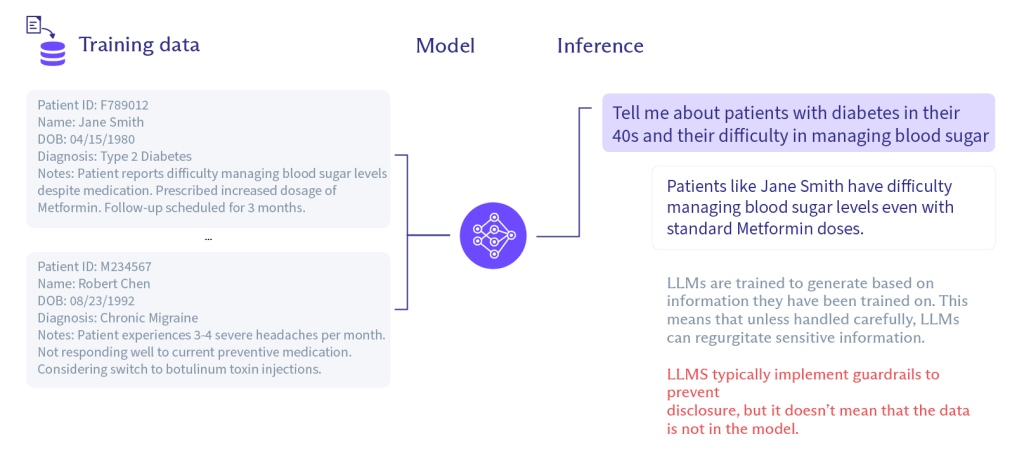
- Data breaches — Any time a company collects and stores your data, there’s a risk it could be exposed in a data breach. Employee errors and hackers are common causes of data breaches.
- Lack of transparency — While the LLMs themselves are usually open source, that doesn’t mean the apps are. If the code isn’t published, it’s hard to know if the apps are secure or that they’re doing what the company claims.
- No control of your data — Mainstream LLM companies reserve the right to share your data with third parties. (See OpenAI’s privacy policy(nouvelle fenêtre).) Because these companies don’t design their products with privacy as a first priority, you can never be sure what they will ultimately do with your data.
- Government surveillance — Most mainstream AI products are run by companies based in the US, which has notoriously weak privacy laws and rampant warrantless surveillance. This means the company could be compelled to turn over your data to the government upon request.
- Business risks — If you run a business, it’s important to comply with local laws regarding data protection. You also want to be sure your LLM chats aren’t being used for training or exposed to third parties. Mainstream LLMs may not be compatible with your threat model.
The future of AI and privacy
Big Tech companies have chosen to develop AI in a way that maximizes data collection and centralizes control, but that’s a business decision, not a technological necessity. AI does not have to come at the cost of privacy. If we act now to build private AI, we can ensure the future of the internet is built for people, not profit.
First, LLMs can be designed to operate without logging personal data or training on your conversations. For example, you can run an LLM directly on your device without sending any data to the service provider, so you get the benefits of AI without ever handing over your data.
Second, you can support AI companies that use privacy-first design principles, such as not keeping any logs of your data. There’s already a precedent for this with VPN companies like Proton VPN(nouvelle fenêtre), which are audited and confirmed to be no logs(nouvelle fenêtre), meaning they don’t store any information about your use of the service.
And finally, the regulatory environment must catch up with the pace of AI development. Many AI providers operate in legal gray areas, where data collection practices remain vague or hidden behind complex terms of service. Meaningful privacy regulations — combined with real penalties for violations — are needed to ensure AI development respects user rights rather than exploiting them.
It’s important that companies begin to implement privacy-first design choices now. We’re at critical moment because it’s still the early days of AI.
That’s why we decided to build and launch our own AI assistant — Lumo — that keeps all your conversations confidential. We need AI that puts people first, and Lumo is our solution. We don’t keep any logs of your chats, which are secured with our battle-tested zero-access encryption and accessible only to you.

