
Les grands modèles de langage (LLMs) formés sur des ensembles de données publics peuvent servir à divers usages, de la rédaction de blogs à la programmation. Cependant, leur véritable potentiel réside dans la contextualisation, obtenue soit par un ajustement du modèle, soit en enrichissant ses invites avec des informations supplémentaires spécifiques. Ce processus implique généralement d’entrer des données personnalisées dans le LLM, qui pourraient contenir des informations sensibles telles que l’historique de messages personnels, des documents internes ou des communications professionnelles. L’absence de garanties de confidentialité robustes dans ces scénarios est l’une des principales raisons pour lesquelles des pays comme l’Italie a imposé des interdictions(nouvelle fenêtre) sur des plateformes comme ChatGPT.
Les LLMs sont des outils incroyables, et nous n’avons fait qu’effleurer la surface de ce qu’ils peuvent faire. Cependant, comme tout outil, les LLMs peuvent être abusés, en particulier pour la surveillance. Dans cet article, nous montrons à quoi nous pensons que l’avenir de l’IA devrait ressembler, un avenir où vous pouvez interagir avec les LLMs et savoir que les informations que vous partagez sont sûres.
Actuellement, vous avez deux options si vous souhaitez exécuter un LLM :
- Localement sur votre appareil : Le LLM fonctionne directement sur votre matériel via votre navigateur et n’interagit jamais avec des serveurs externes. C’est la forme d’inférence IA la plus privée car vos données ne quittent jamais votre machine, mais cela nécessite une machine avec un GPU puissant en raison des calculs intensifs exigés par le LLM.
- Côté serveur : Vos requêtes sont envoyées à des serveurs externes, qui effectuent les calculs LLM à l’aide de GPU haut de gamme. Cette instance d’IA n’a pas d’exigences matérielles spécifiques et peut être exécutée sur presque n’importe quel smartphone, ordinateur portable ou de bureau avec connectivité Internet. Cependant, exécuter des requêtes sur un serveur externe augmente les risques d’exposition des données à moins que les serveurs ne soient sécurisés et ne conservent pas vos demandes ou réponses.
Cet article aborde :
- La performance et l’ouverture de différents LLMs, et explique quels emplois chaque modèle est le mieux adapté à effectuer.
- Les défis techniques présentés par les LLMs sur appareil (par exemple, comment les faire fonctionner localement sur votre appareil).
- Comment les modèles côté serveur fonctionnent, et ce qui peut être fait pour permettre un traitement plus centré sur la vie privée côté serveur.
Modèles
Les LLMs sont formés sur de vastes ensembles de données diversifiés provenant d’Internet, y compris des livres, des articles et des sites Web comme Wikipédia. Cette collecte de données étendue assure que le modèle apprend les nuances du langage, y compris la syntaxe, la sémantique et le contexte.
Le processus de formation implique le prétraitement des données par le biais de la tokenisation, de la normalisation et du filtrage pour garantir la qualité et la cohérence. Utilisant l’architecture Transformer(nouvelle fenêtre), le modèle apprend en prédisant le mot suivant dans une phrase et en ajustant ses paramètres internes pour minimiser les erreurs sur des millions ou milliards d’exemples. Ce processus computationnellement intensif nécessite des ressources importantes impliquant de nombreux GPU puissants et des jours de formation.
Une technique avancée pour affiner les LLMs est l’apprentissage par renforcement à partir des retours humains(nouvelle fenêtre) (RLHF). Dans cette approche, des évaluateurs humains fournissent des retours sur les sorties du modèle, aidant à affiner ses réponses. Les retours sont utilisés pour former un modèle de récompense qui prédit la qualité des réponses, et le LLM est ensuite formé en utilisant des techniques d’apprentissage par renforcement guidées par ce modèle de récompense. Le RLHF garantit que les sorties du modèle s’alignent plus étroitement avec les attentes humaines, améliorant son utilité dans les applications réelles.
Lorsqu’un modèle est formé, vous pouvez alors effectuer inférence, où le modèle formé génère des prédictions ou des réponses basées sur de nouvelles données d’entrée. Cette opération implique plusieurs étapes, à commencer par une version tokenisée de la demande d’un utilisateur. Le modèle traite de nouvelles entrées à travers ses couches de réseau neuronal pour générer une réponse cohérente et contextuellement appropriée. Le modèle convertit alors les tokens générés en texte lisible par l’humain.
Openness du modèle
L’une des grandes réussites depuis le début de ChatGPT a été le travail incroyable effectué pour créer des alternatives ouvertes que tout le monde peut utiliser, démocratisant ainsi les LLMs.
Cependant, bien que les développeurs devraient être loués pour leurs efforts, nous devrions aussi être prudents face au “lavage ouvert”, semblable au “washing de la vie privée” ou “greenwashing”, où des entreprises affirment que leurs modèles sont “ouverts”, mais qu’en réalité seule une petite partie l’est.
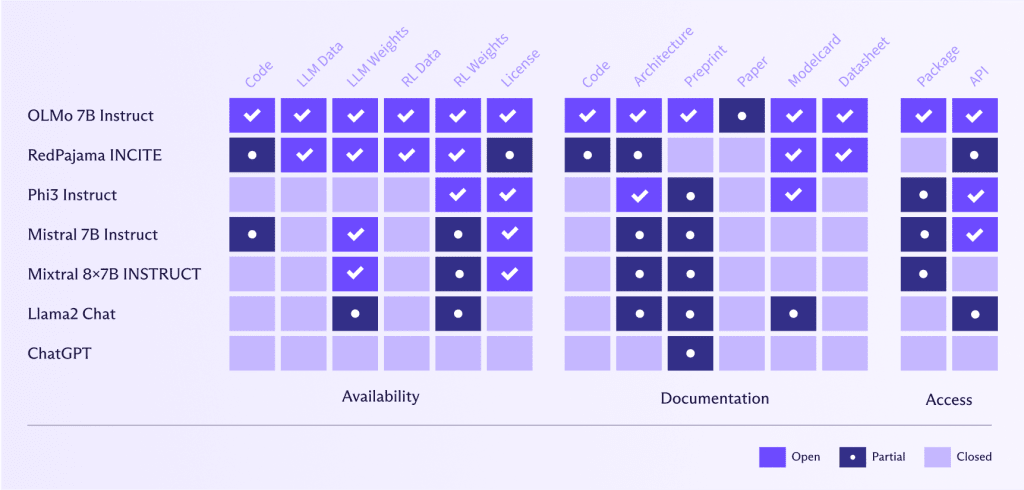
Les LLMs ouverts comme OLMo 7B Instruct(nouvelle fenêtre) offrent des avantages significatifs en termes de benchmarking, de reproductibilité, de transparence algorithmique, de détection des biais et de collaboration communautaire. Ils permettent une évaluation rigoureuse des performances et la validation de la recherche en IA, ce qui à son tour favorise la confiance et permet à la communauté d’identifier et de traiter les biais. Les efforts collaboratifs mènent à des améliorations et des innovations partagées, accélérant ainsi les avancées en IA. De plus, les LLMs ouverts offrent de la flexibilité pour des solutions sur mesure et des expérimentations, permettant aux utilisateurs de personnaliser et d’explorer de nouvelles applications et méthodologies.
En démocratisant l’accès à une IA avancée, les LLMs ouverts aident à prévenir la concentration des capacités d’IA au sein de quelques grandes entreprises technologiques, favorisant ainsi une distribution du pouvoir plus équilibrée.
À l’inverse, Meta ou OpenAI, par exemple, ont une définition de “ouvert” très différente de celle de AllenAI(nouvelle fenêtre) (l’institut derrière OLMo 7B Instruct). Ces entreprises ont rendu leur code, leurs données, leurs poids et leurs recherches seulement partiellement disponibles ou ne les ont pas partagés du tout.
L’ouverture dans les LLMs est cruciale pour la vie privée et l’utilisation éthique des données, car elle permet aux gens de vérifier quelles données le modèle a utilisées et si ces données ont été collectées de manière responsable. En rendant les LLMs ouverts, la communauté peut examiner et vérifier les ensembles de données, garantissant que les informations personnelles sont protégées et que les pratiques de collecte de données respectent les normes éthiques. Cette transparence favorise la confiance et la responsabilité, essentielles pour le développement de technologies IA qui respectent la vie privée des utilisateurs et respectent des principes éthiques.
Taille et performance du modèle
Grands modèles
Jusqu’à présent, la taille compte en ce qui concerne les LLMs : les modèles plus grands obtiennent de meilleurs résultats que les plus petits pour les raisons suivantes :
- Capacité à apprendre des motifs complexes : Avec plus de paramètres (plus de 70 milliards pour Llama3), les modèles plus grands peuvent apprendre et représenter des motifs plus complexes dans les données. Cela leur permet de générer des réponses plus précises et nuancées.
- Meilleure généralisation : Les modèles plus grands peuvent mieux généraliser des données d’apprentissage aux données non vues. Ils peuvent capturer une plus large gamme de structures et de nuances linguistiques, ce qui améliore les performances dans diverses tâches.
- Compréhension contextuelle plus élevée : Les modèles plus grands peuvent maintenir et traiter des contextes plus longs, leur permettant de générer des réponses plus cohérentes et contextuellement appropriées. C’est particulièrement important pour les tâches qui nécessitent une compréhension de textes étendus, comme la synthèse et la génération de dialogues.
- Amélioration de l’ajustement fin : Les modèles plus grands offrent une meilleure base pour un ajustement fin sur des tâches ou des domaines spécifiques. Ils peuvent tirer parti de leurs vastes connaissances pré-entraînées pour s’adapter plus efficacement à des ensembles de données spécialisés, améliorant les performances dans des applications spécifiques.
Les grands modèles, avec leur grand nombre de paramètres (et donc de poids), prennent beaucoup de mémoire et nécessitent des ressources CPU ou GPU considérables pour effectuer l’inférence efficacement. Donc, même si GPT4 était ouvert, son exécution serait toujours prohibitive.
Cependant, il existe certaines façons de rendre les grands modèles plus petits sans sacrifier drastiquement leur performance, y compris :
- Quantification des modèles : C’est lorsque des représentations de poids de modèle à virgule flottante, grandes et gourmands en mémoire, sont converties en représentations de 8 bits ou 4 bits, permettant aux LLMs d’utiliser des arithmétiques de précision inférieure. Cela réduit considérablement les exigences en mémoire et en calcul de l’appareil sans sacrifier beaucoup l’exactitude du modèle.
“Quantification et formation des réseaux neuronaux pour une inférence efficace uniquement en arithmétique entière” par Jacob et al., 2018. “Llm. int8 : multiplication matricielle 8 bits pour transformers à grande échelle” par Dettmers et al., 2022. - Élagage des poids : Cela implique de supprimer les poids moins significatifs du modèle, réduisant sa taille et ses demandes de calcul tout en maintenant l’exactitude.
“Learning both Weights and Connections for Efficient Neural Networks” par Han et al., 2015.
Puis, enfin, il y a l’option pour des modèles plus petits, plus spécialisés et moins gourmands en ressources.
Modèles plus petits
Avec un nombre de paramètres plus petit, les modèles plus petits nécessitent également moins de calculs au moment de l’inférence, ce qui les rend plus rapides et moins gourmands en ressources en termes de mémoire et d’utilisation de GPU, ouvrant la porte à l’exécution des LLMs directement sur un appareil grand public.
Bien que les modèles plus petits ne soient généralement pas aussi performants que les modèles plus grands, il existe plusieurs façons de les faire se comporter davantage comme des modèles plus grands pour des tâches spécifiques. Cela inclut :
- Distillation des connaissances : C’est lorsque un modèle grand et pré-entraîné (enseignant) est utilisé pour former un modèle plus petit (élève) qui imite la performance du modèle plus grand mais avec moins de paramètres, le rendant plus adapté à l’exécution sur appareil.
“Distilling the Knowledge in a Neural Network” par Hinton, Vinyals et Dean, 2015. “DistilBERT, une version distillée de BERT : plus petit, plus rapide, moins cher et plus léger” par Sanh et al., 2019. - Mélange d’experts (MoE) : Les modèles MoE, comme Mixtral 8x7B, améliorent les performances en combinant plusieurs modèles spécialisés plus petits (experts), chacun se concentrant sur différents aspects des données d’entrée (par exemple, un modèle pour la ponctuation, un pour les verbes, un autre pour les nombres, etc.). Un mécanisme de sélection dynamique choisi les experts les plus pertinents pour chaque entrée, garantissant qu’un sous-ensemble est activé, réduisant les coûts computationnels et améliorant l’efficacité. Cette approche permet aux modèles MoE de se spécialiser et de se mettre à l’échelle efficacement tout en fournissant une précision élevée et une robustesse à travers diverses tâches sans augmentation proportionnelle des demandes computationnelles.
Les modèles comme Mixtral 8x7B Instruct surclassent des modèles comme Llama2, avec ses 70 milliards de paramètres, en termes de leur capacité à générer un contenu cohérent, mais sont également six fois plus rapides pour effectuer l’inférence.
Pour des modèles très grands, les modèles Mixtral 8x22B peuvent fonctionner au même niveau, voire mieux que GPT4 et GPT3.5. Étant donné que GPT4 utilise 1,76 trillion de paramètres, il est impressionnant qu’un modèle avec un ordre de grandeur de paramètres inférieur puisse fonctionner de manière similaire.
LLM sur appareil
La nature ouverte des modèles et les développements ultérieurs par des chercheurs et des ingénieurs ont conduit à des LLM pouvant fonctionner sur un appareil utilisateur sans perte dramatique d’exactitude ou de vitesse.
Les LLM sur appareil peuvent offrir des capacités d’IA puissantes tout en préservant la vie privée des utilisateurs et fonctionnent donc dans des environnements E2EE. Quelques projets open source, notamment Llamacpp(nouvelle fenêtre) et WebLLM(nouvelle fenêtre), facilitent l’exécution des LLM en local.
Llamacpp(nouvelle fenêtre) est une bibliothèque open source C++ permettant d’exécuter votre propre API compatible OpenAI sur un LLM sur votre machine (ou serveur) utilisant des CPU ou GPU. Une des techniques d’optimisation clés utilisées dans llama.cpp est la quantification, qui réduit considérablement l’empreinte mémoire et accélère l’inférence sans sacrifices importants sur l’exactitude.
Llamacpp nécessite que les modèles soient chargés à partir du format unifié généré par GPT (GGUF), un format binaire personnalisé qui stocke efficacement les paramètres des modèles d’apprentissage automatique. Il est conçu pour optimiser le stockage et l’accès aux poids des modèles, en particulier dans des scénarios où les modèles doivent être chargés rapidement et utilisés dans des environnements à mémoire limitée.
Le projet WebLLM(nouvelle fenêtre) vous permet d’exécuter des LLM directement dans votre navigateur web. WebLLM exploite la puissance de WebGPU(nouvelle fenêtre) et l’optimisation d’Apache TVM(nouvelle fenêtre).
Apache TVM est un compilateur open source pour l’apprentissage automatique qui joue un rôle crucial dans la réalisation de WebLLM grâce à :
- Transformation de modèle: Les modèles conçus dans des frameworks de haut niveau comme TensorFlow ou PyTorch sont importés dans TVM. TVM convertit ensuite ces modèles en une représentation intermédiaire (IR) pouvant être optimisée pour la performance.
- Optimisation: TVM effectue une série d’optimisations sophistiquées sur cette IR. Elle fusionne les opérations pour réduire l’accès mémoire redondant, planifie efficacement l’utilisation de la mémoire et restructure les graphes de calcul pour un maximum de parallélisme. Cette étape est clé pour faire fonctionner les modèles rapidement et efficacement sur le GPU de votre navigateur.
- Génération de code: Une fois optimisé, TVM génère du code adapté pour WebGPU. Cela implique de compiler des noyaux et de créer du code d’exécution pouvant s’exécuter efficacement sur le GPU.
WebGPU est une API graphique moderne conçue pour donner aux applications web un accès direct à la puissance des GPU. Pour WebLLM, WebGPU est le moteur qui exécute le code finement réglé généré par Apache TVM. Voici comment cela s’intègre dans l’ensemble:
- Gestion des ressources: WebGPU gère l’allocation et la gestion de la mémoire GPU pour les paramètres du modèle, les données d’entrée et les calculs, garantissant l’utilisation efficace des ressources.
- Exécution de shader: Il compile et exécute des shaders – de petits programmes sur le GPU – qui effectuent le travail lourd des opérations de réseau neuronal.
- Gestion des commandes: WebGPU encode et soumet des commandes au GPU, orchestrant l’exécution du code optimisé et garantissant un fonctionnement fluide.
Pour le moment, le support WebGPU(nouvelle fenêtre) n’est pas présent dans tous les navigateurs, du moins pas par défaut. Safari, par exemple, n’a ajouté le support que récemment dans sa version “Technology Preview”, et Firefox nécessite d’activer un drapeau appelé dom.webgpu.enabled. Pratiquement aucun navigateur mobile, à part ceux basés sur Chromium, ne prend en charge WebGPU. Ces réserves rendent difficile le soutien par défaut de tous les utilisateurs.
Il existe également d’autres considérations, en plus du manque de support WebGPU, qui rendent l’exécution des modèles dans le navigateur difficile. Pour exécuter un modèle localement, vous devez disposer de:
- Bande passante suffisante: Vous devez télécharger un modèle de plusieurs Go (de nouveau, des modèles plus grands donneront généralement de meilleurs résultats).
- Un GPU raisonnablement puissant: Si vous avez un Mac, n’importe quel appareil Apple M peut exécuter un modèle de 7 milliards de paramètres. Si vous utilisez Windows ou Linux, un GPU dédié avec 6 Go de VRAM exécutera un LLM.
Comme vous pouvez le constater, il est déjà possible de faire fonctionner un LLM personnalisé avec un accès sécurisé à vos données personnalisées sur votre ordinateur ou smartphone — tant que votre appareil est suffisamment puissant. Malheureusement, cette exigence exclut beaucoup de personnes. La plupart des modèles sont également de taille prohibitive, rendant leur téléchargement difficile dans des lieux éloignés ou dans des pays avec une infrastructure Internet de mauvaise qualité.
L’avenir de l’appareil
Bien que la capacité d’exécuter des LLM sur appareil soit actuellement limitée aux meilleurs, aux plus puissants et aux plus coûteux appareils, nous avons déjà constaté des progrès technologiques remarquables au cours des deux dernières années pour rendre les LLM accessibles à tous. Les tendances que nous observons aujourd’hui continueront probablement à évoluer vers:
- Local par défaut: Les LLM coûtent cher à exécuter, donc déléguer la génération au client a du sens à la fois du point de vue de la vie privée et des coûts. Plus de soutien pour WebGPU facilitera l’exécution des modèles dans leurs navigateurs à tous les utilisateurs.
- Des LLM plus petits: les LLM spécifiques à une tâche deviendront plus courants, vous permettant de passer d’un modèle à l’autre en fonction des tâches — par exemple, un pour les e-mails, un pour la création de documents, un pour les images, l’audio, la recherche, etc. Les modèles plus petits fonctionnent plus rapidement et montrent déjà qu’ils performent aussi bien, et, dans certains cas, mieux que(nouvelle fenêtre) les grands modèles comme GPT 4 dans des tâches spécifiques.
- LLM dans les SDK/navigateur: Les développeurs d’applications pourront bientôt appeler les LLM tout comme ils appellent d’autres fonctionnalités dans un SDK, comme obtenir l’accès à la caméra de l’utilisateur dans une application Android. Cela facilitera l’intégration des LLM et, si manipulé sur appareil, sera également privé par défaut.
LLM côté serveur
Les modèles côté serveur restent la méthode la plus rapide et la plus fiable pour exécuter des LLM, assurant une performance robuste et une stabilité.
Exécuter des LLM sur votre propre machine renforce votre vie privée mais nécessite un matériel puissant pour gérer efficacement les demandes de calcul.
Nous avons déjà vu comment LlamaCPP peut être utilisé pour exécuter des modèles sur des appareils de consommation, mais il peut également être utilisé sur des serveurs, fournissant les interfaces pour exécuter des modèles de manière performante sur des GPU haut de gamme. Il prend en charge les fonctionnalités nécessaires pour exécuter des LLM dans des environnements plus proches de la production avec parallélisme (pour servir plusieurs utilisateurs en même temps), des jetons d’accès (pour fournir un accès au serveur uniquement à ceux ayant la permission), SSL (pour chiffrer le trafic d’un client vers un serveur) et la surveillance de la santé (pour s’assurer que votre système fonctionne).
Modèles côté serveur
Bien que les modèles mentionnés précédemment pour sur appareil puissent également fonctionner côté serveur, il est généralement logique d’exécuter des modèles plus puissants pour obtenir de meilleures performances (si besoin). En regardant le graphique ci-dessous, vous verrez comment les modèles Mixtral 8x22B se comparent à GPT 4 Turbo ou GPT 3.5 Turbo. Si vous souhaitez des performances de modèle au niveau de ChatGPT, vous pouvez déjà vous en approcher.
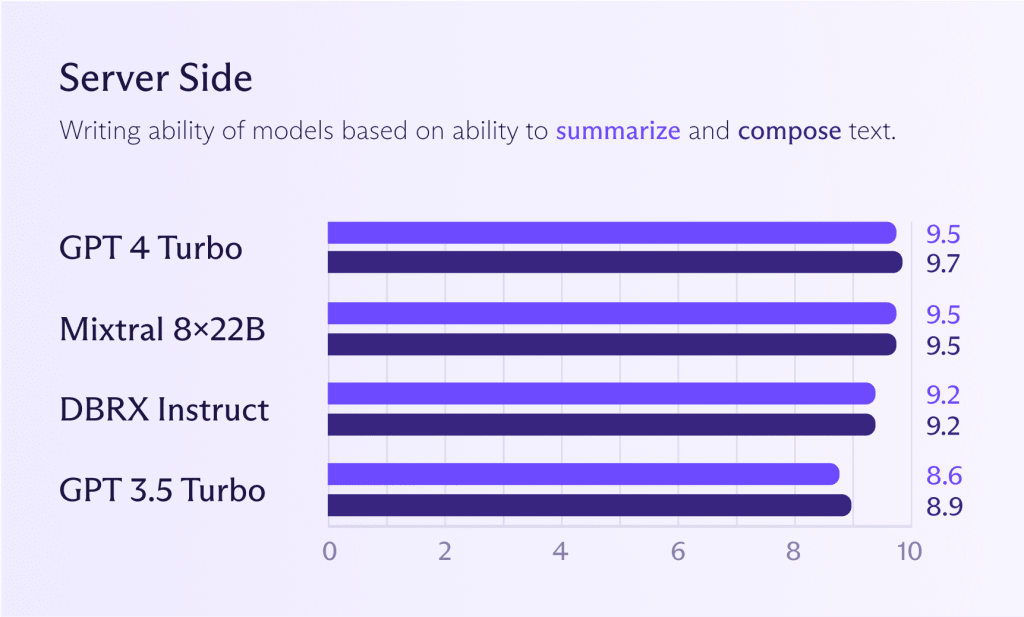
Cependant, comme mentionné précédemment, il est discutable que vous ayez besoin de performances au niveau de ChatGPT pour la plupart des tâches. Utiliser un grand modèle pour toutes les tâches est coûteux, comme engager un chef gourmet pour faire bouillir des pommes de terre. Le chef le fera, mais vous paierez un prix élevé pour ce privilège. Juste parce que vous pouvez ne signifie pas que vous devriez.
L’avenir de l’inférence côté serveur
Le chiffrement homomorphe (HE) est une approche prometteuse, bien que toujours en développement, pour permettre une inférence préservant la vie privée sur les LLM à travers les réseaux.
LE HE est important car il offre une manière puissante de travailler avec des données chiffrées. Il permet d’effectuer des calculs sur des textes chiffrés qui, une fois déchiffrés, donnent le même résultat que si les opérations avaient été effectuées sur le texte clair. Cette caractéristique rend le HE particulièrement intrigant pour des applications impliquant des données sensibles, notamment le travail avec des LLM.
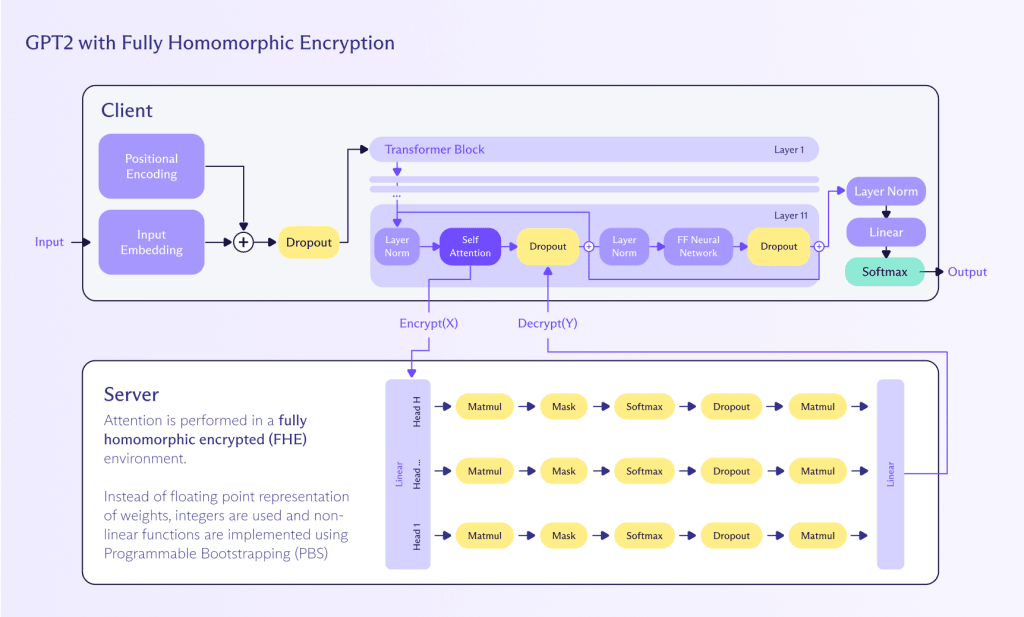
Le calcul homomorphe est une méthode de réalisation de calculs sur des données chiffrées sans avoir besoin de les déchiffrer au préalable. Cette approche préserve la vie privée et la sécurité tout au long du processus de calcul. Voici comment cela peut être appliqué pour réaliser une inférence sur un LLM:
- Chiffrement: L’entrée utilisateur (par exemple, le texte) est chiffrée à l’aide d’un schéma de chiffrement homomorphe. Cela garantit que les données d’entrée restent confidentielles et sécurisées.
- Calcul: Le LLM, qui a été adapté pour prendre en charge les opérations homomorphes, traite l’entrée chiffrée. Le modèle effectue ses calculs directement sur les données chiffrées, générant une sortie chiffrée.
- Déchiffrement: Le résultat chiffré produit par le LLM est ensuite déchiffré pour fournir la sortie texte claire finale à l’utilisateur.
Bien que le chiffrement homomorphe existe déjà, il en est encore à ses débuts et ne peut pas encore se développer pour gérer les LLM pour plusieurs raisons:
- Performance: Le chiffrement homomorphe est intensif en calcul et peut considérablement ralentir le processus d’inférence. Des avancées en matière de matériel et de techniques d’optimisation sont nécessaires pour rendre cette approche pratique pour des applications en temps réel.
- Adaptation du modèle: Les LLM existants doivent être adaptés pour prendre en charge les opérations homomorphes, ce qui peut être complexe et nécessiter des connaissances spécialisées en cryptographie et en apprentissage automatique.
- Scalabilité: Assurer que le schéma de chiffrement homomorphe peut évoluer pour traiter de grands modèles et de grands volumes de données est crucial pour une adoption généralisée.
Zama(nouvelle fenêtre), par exemple, essaie d’intégrer le chiffrement homomorphe complet (FHE) dans des algorithmes ML et dispose d’un exemple fonctionnel(nouvelle fenêtre) de la façon de le faire avec des modèles GPT-2, bien que lentement (et cher). Cependant, comme Zama l’explique(nouvelle fenêtre), il existe un chemin vers les LLM FHE dans les prochaines années grâce à une compression LLM supplémentaire, des améliorations de la cryptographie derrière le FHE et un matériel dédié dont l’accélération est prévue pour 2025.
La confidentialité est l’avenir de l’IA
L’IA générative est potentiellement un développement qui définit une génération — une préoccupation du communauté Proton, comme en témoigne notre sondage 2024. Les récents développements technologiques ont rendu les LLM plus ouverts, plus petits et plus rapides, ouvrant de nouvelles possibilités pour GenAI.
Aujourd’hui, de nombreuses personnes peuvent déjà exécuter un assistant IA personnalisé et entièrement privé sur leur appareil en combinant ces LLM avec leur propre contenu — quelque chose qui n’était possible que dans le domaine de la science-fiction il y a quelques années.
La prochaine frontière est d’apporter ce niveau de performance aux personnes ayant des limitations de connectivité ou d’appareil. Le FHE semble pouvoir combler cette lacune, permettant des LLM chiffrés et respectant la vie privée dans un avenir proche. Jusqu’à présent, les modèles côté serveur fonctionnant sur des GPU hautes performances resteront le moyen le plus rapide de générer du contenu dans ces conditions défavorables, mais au prix possible de certaines niveaux de confidentialité.
Si vous souhaitez travailler à la construction d’IA respectueuses de la vie privée et de technologies connexes, consultez notre page carrières pour d’éventuelles ouvertures.





