
Große Sprachmodelle (LLMs), die auf öffentlichen Datensätzen trainiert sind, können eine Vielzahl von Zwecken erfüllen, von der Erstellung von Blogposts bis zur Programmierung. Ihr wahres Potenzial liegt jedoch in der Kontextualisierung, die durch Feinabstimmung des Modells oder durch Anreicherung seiner Eingabewerte mit spezifischen Zusatzinformationen erreicht wird. Dieser Prozess beinhaltet typischerweise die Eingabe von benutzerdefinierten Daten in das LLM, die möglicherweise sensible Materialien wie persönliche Nachrichtenverläufe, interne Unternehmensdokumente oder Kommunikationsverläufe enthält. Das Fehlen robuster Datenschutzvorkehrungen in diesen Szenarien ist einer der Hauptgründe, warum Länder wie Italien verbote erlassen haben(neues Fenster) für Plattformen wie ChatGPT.
LLMs sind unglaubliche Werkzeuge, und wir haben erst begonnen, die Möglichkeiten zu erkunden. Aber wie jedes Werkzeug können LLMs missbraucht werden, insbesondere zur Überwachung. In diesem Artikel zeigen wir, wie wir uns die Zukunft der KI vorstellen, in der du mit LLMs interagieren kannst und weißt, dass die Informationen, die du teilst, sicher sind.
Derzeit hast du zwei Optionen, wenn du ein LLM betreiben möchtest:
- Lokal auf deinem Gerät: Das LLM läuft direkt auf deiner Hardware über deinen Browser und kommuniziert niemals mit externen Servern. Dies ist die privateste Form der KI-Inferenz, da deine Daten niemals deinen Computer verlassen, aber es erfordert eine Maschine mit einer leistungsstarken GPU aufgrund der intensiven Berechnungen, die das LLM erfordert.
- Server-seitig: Deine Anfragen werden an externe Server gesendet, die die LLM-Berechnungen mit High-End-GPUs durchführen. Diese KI-Instanz hat keine spezifischen Hardware-Anforderungen und kann auf fast jedem Smartphone, Laptop oder Desktop mit Internetverbindung ausgeführt werden. Die Ausführung von Anfragen auf einem externen Server erhöht jedoch die Risiken einer Datenerfassung, es sei denn, die Server sind gesichert und protokollieren deine Eingaben oder Antworten nicht.
Dieser Artikel befasst sich mit:
- Der Leistung und Offenheit verschiedener LLMs und erklärt, welche Aufgaben jedes Modell am besten erfüllen kann.
- Die technischen Herausforderungen dargestellt durch LLMs auf dem Gerät (zum Beispiel, wie man sie lokal auf deinem Gerät ausführt).
- Wie Server-seitige Modelle funktionieren und was getan werden kann, um eine datenschutzorientierte Serververarbeitung zu ermöglichen.
Modelle
LLMs werden auf umfangreichen, vielfältigen Datensätzen trainiert, die aus dem Internet stammen, einschließlich Bücher, Artikel und Webseiten wie Wikipedia. Diese umfangreiche Datensammlung stellt sicher, dass das Modell die Nuancen der Sprache, einschließlich Syntax, Semantik und Kontext, erlernt.
Der Trainingsprozess umfasst die Vorverarbeitung der Daten durch Tokenisierung, Normalisierung und Filterung, um Qualität und Konsistenz sicherzustellen. Mit Transformatorarchitektur(neues Fenster) lernt das Modell durch die Vorhersage des nächsten Wortes in einem Satz und passt seine internen Parameter an, um Fehler über Millionen oder Milliarden von Beispielen zu minimieren. Dieser rechenintensive Prozess erfordert erhebliche Ressourcen, einschließlich vieler leistungsstarker GPUs und Tage des Trainings.
Eine fortgeschrittene Technik zur Verfeinerung von LLMs ist Verstärkendes Lernen aus menschlichem Feedback(neues Fenster) (RLHF). In diesem Ansatz geben menschliche Evaluatoren Feedback zu den Ausgaben des Modells, das dazu beiträgt, die Antworten zu verfeinern. Das Feedback wird verwendet, um ein Belohnungsmodell zu trainieren, das die Qualität der Antworten vorhersagt, und das LLM wird weiter mit verstärkenden Lerntechniken trainiert, die von diesem Belohnungsmodell geleitet werden. RLHF stellt sicher, dass die Ausgaben des Modells enger an den menschlichen Erwartungen ausgerichtet sind, wodurch die Anwendbarkeit in realen Anwendungen verbessert wird.
Wenn ein Modell trainiert ist, kannst du dann Inferenz durchführen, bei der das trainierte Modell Vorhersagen oder Antworten basierend auf neuen Eingabedaten generiert. Dieser Vorgang umfasst mehrere Schritte, beginnend mit einer tokenisierten Version der Eingabe eines Benutzers. Das Modell verarbeitet neue Eingaben über seine neuronalen Netzwerkschichten, um eine kohärente und kontextuell angemessene Antwort zu erzeugen. Das Modell konvertiert die erzeugten Tokens dann zurück in lesbaren Text.
Modell Offenheit
Eine der großartigen Erfolgsgeschichten seit dem Aufkommen von ChatGPT war die unglaubliche Arbeit, offene Alternativen zu schaffen, die jeder nutzen kann, wodurch LLMs demokratisiert werden.
Wenn auch Entwickler für ihre Bemühungen gelobt werden sollten, sollten wir auch vorsichtig sein bei “offenem Waschen”, ähnlich wie “Datenschutz-Waschen” oder “Greenwashing”, wo Unternehmen sagen, dass ihre Modelle “offen” sind, aber tatsächlich nur ein kleiner Teil ist.
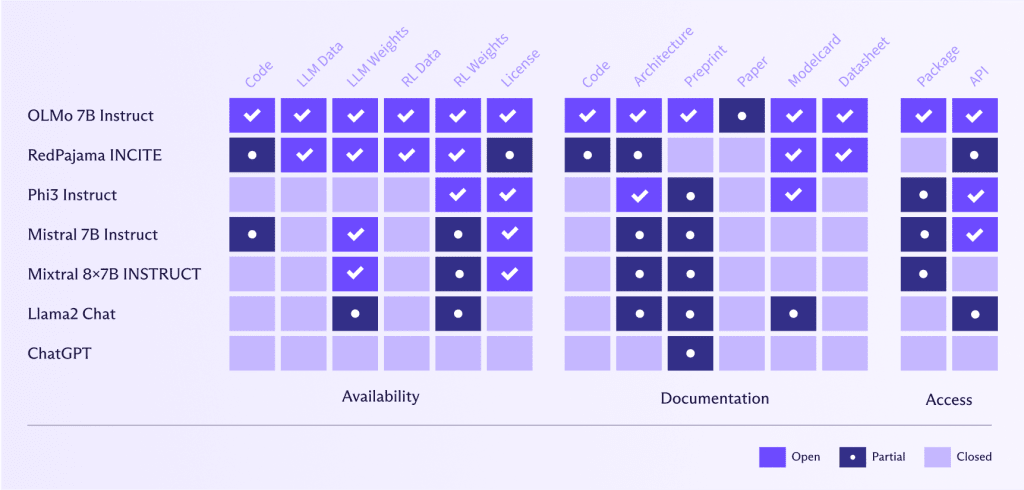
Offene LLMs wie OLMo 7B Instruct(neues Fenster) bieten erhebliche Vorteile bei Benchmarking, Reproduzierbarkeit, algorithmischer Transparenz, Bias-Erkennung und Zusammenarbeit in der Gemeinschaft. Sie ermöglichen rigorose Leistungsbewertung und Validierung von KI-Forschung, was wiederum Vertrauen fördert und der Gemeinschaft hilft, Vorurteile zu erkennen und anzugehen. Gemeinsame Anstrengungen führen zu gemeinsamen Verbesserungen und Innovationen, die Fortschritte in der KI beschleunigen. Außerdem bieten offene LLMs Flexibilität für maßgeschneiderte Lösungen und Experimente, die es den Benutzern ermöglichen, neue Anwendungen und Methoden zu erkunden und anzupassen.
Durch die Demokratisierung des Zugangs zu fortschrittlicher KI helfen offene LLMs, die Konzentration von KI-Fähigkeiten innerhalb einiger dominierender Technologieunternehmen zu verhindern und eine ausgewogenere Machtverteilung zu fördern.
Im Gegensatz dazu haben Meta oder OpenAI beispielsweise eine sehr andere Definition von “offen” als AllenAI(neues Fenster) (das Institut hinter OLMo 7B Instruct). Diese Unternehmen haben ihren Code, Daten, Gewichte und Forschungsarbeiten nur teilweise verfügbar gemacht oder sie nicht geteilt .
Die Offenheit von LLMs ist entscheidend für den Datenschutz und die ethische Datennutzung, da sie es den Menschen ermöglicht zu überprüfen, welche Daten das Modell verwendet hat und ob diese Daten verantwortungsbewusst beschafft wurden. Durch die Offenheit von LLMs kann die Gemeinschaft die Datensätze überprüfen und garantieren, dass persönliche Informationen geschützt sind und die Praktiken zur Datensammlung ethischen Standards entsprechen. Diese Transparenz fördert Vertrauen und Verantwortung, die entscheidend für die Entwicklung von KI-Technologien sind, die die Privatsphäre der Benutzer respektieren und ethische Prinzipien wahren.
Modellgröße und Leistung
Große Modelle
Bisher zählt die Größe bei LLMs – größere Modelle schneiden besser ab als kleinere Modelle aus folgenden Gründen:
- Kapazität zum Erlernen komplexer Muster: Mit mehr Parametern (über 70 Milliarden für Llama3) können größere Modelle komplexere Muster in den Daten lernen und darstellen. Dies ermöglicht ihnen, genauere und nuanciertere Antworten zu generieren.
- Bessere Verallgemeinerung: Größere Modelle können besser von Trainingsdaten auf unbekannte Daten verallgemeinern. Sie können ein breiteres Spektrum an sprachlichen Strukturen und Nuancen erfassen, was zu einer verbesserten Leistung über verschiedene Aufgaben hinweg führt.
- Höhere kontextuelle Verständnis: Größere Modelle können längere Kontexte beibehalten und verarbeiten, was es ihnen ermöglicht, kohärentere und kontextuell angemessenere Antworten zu generieren. Das ist besonders wichtig für Aufgaben, die ein Verständnis verlängerter Texte erfordern, wie Zusammenfassungen und Dialoggenerierungen.
- Verbesserte Feinabstimmung: Größere Modelle bieten eine bessere Grundlage für die Feinabstimmung auf spezifische Aufgaben oder Bereiche. Sie können ihr umfassendes vortrainiertes Wissen effektiver nutzen, um sich an spezialisierte Datensätze anzupassen und die Leistung in bestimmten Anwendungen zu verbessern.
Große Modelle mit ihrer großen Anzahl an Parametern (und damit Gewichten) benötigen viel Speicher und erfordern erhebliche CPU- oder GPU-Ressourcen, um Inferenz effektiv durchzuführen. Selbst wenn GPT4 offen wäre, wäre es dennoch prohibitv teuer, es auszuführen.
Es gibt jedoch einige Möglichkeiten, große Modelle kleiner zu machen, ohne die Leistung dramatisch zu opfern, einschließlich:
- Modellquantisierung: Hierbei werden große, speicherintensive, Gleitkommadarstellungen der Modellgewichte in 8-Bit- oder 4-Bit-Darstellungen umgewandelt, wodurch LLMs niedrigere Rechenoperationen verwenden können. Dies reduziert erheblich den Speicher- und Rechenbedarf des Geräts, ohne die Genauigkeit des Modells stark zu opfern.
“Quantisierung und Training von neuronalen Netzen für effiziente Inferenz mit ganzzahlarithmetischen Operationen” von Jacob et al., 2018. “Llm. int8: 8-Bit-Matrixmultiplikation für Transformatoren im großen Maßstab” von Dettmers et al., 2022. - Gewichtsreduktion: Hierbei werden weniger signifikante Gewichte aus dem Modell entfernt, wodurch die Größe und die Rechenanforderungen verringert werden, während die Genauigkeit beibehalten bleibt.
“Lernen sowohl von Gewichten als auch von Verbindungen für effiziente neuronale Netzwerke” von Han et al., 2015.
Und schließlich gibt es die Option für kleinere, spezialisierte, weniger ressourcenintensive Modelle.
Kleinere Modelle
Mit einer geringeren Anzahl von Parametern erfordern kleinere Modelle auch weniger Berechnungen zur Inferenz, wodurch sie schneller und weniger ressourcenintensiv in Bezug auf Speicher und GPU-Nutzung werden, was die Durchführung von LLMs direkt auf einem Verbrauchsgerät ermöglicht.
Obwohl kleinere Modelle typischerweise nicht so gut abschneiden wie größere Modelle, da sie nicht in der Lage sind, nuanciertere Muster im Text zu erfassen, gibt es mehrere Möglichkeiten, wie wir kleinere Modelle dazu bringen können, sich für bestimmte Aufgaben mehr wie größere zu verhalten. Dazu gehören:
- Wissensdestillation: Hierbei wird ein großes, vortrainiertes Modell (Lehrer) verwendet, um ein kleineres Modell (Schüler) zu trainieren, das die Leistung des größeren Modells mit weniger Parametern nachahmt und somit besser für die Ausführung auf Geräten geeignet ist.
“Das Wissen in einem neuronalen Netzwerk destillieren” von Hinton, Vinyals und Dean, 2015. “DistilBERT, eine destillierte Version von BERT: kleiner, schneller, günstiger und leichter” von Sanh et al., 2019. - Mischung von Experten (MoE): MoE-Modelle, wie Mixtral 8x7B, verbessern die Leistung, indem sie mehrere spezialisierte, kleinere Modelle (Experten) kombinieren, die sich jeweils auf verschiedene Aspekte der Eingabedaten konzentrieren (zum Beispiel ein Modell für Satzzeichen, eines für Verben, eines für Zahlen usw.). Ein Steuermechanismus wählt dynamisch die relevantesten Experten für jede Eingabe aus, sodass nur ein Teil aktiviert wird, was die Rechenkosten senkt und die Effizienz verbessert. Dieser Ansatz ermöglicht es MoE-Modellen, sich zu spezialisieren und effektiv zu skalieren, während sie gleichzeitig hohe Genauigkeit und Robustheit über vielfältige Aufgaben hinweg bieten, ohne proportionale Erhöhungen der Rechenanforderungen.
Modelle wie Mixtral 8x7B Instruct übertreffen Modelle wie Llama2 mit seinen 70 Milliarden Parametern in Bezug auf ihre Fähigkeit, kohärente Inhalte zu erzeugen, sind aber auch sechsmal schneller bei der Inferenz.
Für sehr große Modelle können Mixtral 8x22B-Modelle auf dem gleichen Niveau oder sogar besser als GPT4 und GPT3.5 abschneiden. Angesichts der Tatsache, dass GPT4 angeblich 1,76 Billionen Parameter verwendet, ist es beeindruckend, dass ein Modell mit einer Größenordnung weniger Parametern ähnlich abschneiden kann.
Auf Gerät LLMs
Die offene Natur der Modelle und anschließende Entwicklungen von Forschern und Ingenieuren haben zu LLMs geführt, die auf einem Benutzergerät ohne dramatische Einbußen bei Genauigkeit oder Geschwindigkeit laufen können.
Auf Gerät LLMs können leistungsstarke KI-Funktionen liefern und dabei die Privatsphäre der Benutzer wahren, sodass sie in E2EE-Einstellungen funktionieren. Einige Open-Source-Projekte, insbesondere Llamacpp(neues Fenster) und WebLLM(neues Fenster), erleichtern es, LLMs lokal auszuführen.
Llamacpp(neues Fenster) ist eine Open-Source-C++-Bibliothek, die es dir ermöglicht, deine eigene OpenAI-kompatible API auf einem LLM auf deiner Maschine (oder deinem Server) unter Verwendung von CPUs oder GPUs auszuführen. Eine der Hauptoptimierungstechniken, die in llama.cpp verwendet wird, ist Quantisierung, die den Speicherbedarf erheblich reduziert und die Inferenz beschleunigt, ohne große Einbußen bei der Genauigkeit.
Llamacpp benötigt Modelle im GPT-Generated Unified Format (GGUF), einem benutzerdefinierten Binärformat, das die Parameter von Maschinenlernen-Modellen effizient speichert. Es wurde entwickelt, um die Speicherung und den Zugriff auf Modellgewichte zu optimieren, insbesondere für Szenarien, in denen Modelle schnell geladen und in speicherbeschränkten Umgebungen verwendet werden müssen.
Das WebLLM(neues Fenster)-Projekt ermöglicht es dir, LLMs direkt in deinem Webbrowser auszuführen. WebLLM nutzt die Leistung von WebGPU(neues Fenster) und die Optimierungsmöglichkeiten von Apache TVM(neues Fenster).
Apache TVM ist ein Open-Source-Maschinenlernen-Compiler, der eine entscheidende Rolle dabei spielt, WebLLM möglich zu machen, indem er:
- Modellverwandlung: Modelle, die in hochgradigen Frameworks wie TensorFlow oder PyTorch erstellt wurden, werden in TVM importiert. TVM konvertiert diese Modelle dann in eine Zwischenrepräsentation (IR), die für die Leistung optimiert werden kann.
- Optimierung: TVM führt eine Reihe komplexer Optimierungen an diesem IR durch. Es fusioniert Operationen, um redundanten Speicherzugriff zu reduzieren, plant den Speicherbedarf effizient und restrukturiert Berechnungsgrafen für maximale Parallelität. Dieser Schritt ist entscheidend dafür, dass Modelle schnell und schlank auf der GPU deines Browsers laufen.
- Codegenerierung: Nach der Optimierung generiert TVM Code, der auf WebGPU zugeschnitten ist. Das umfasst das Kompilieren von Kerneln und das Erstellen von Laufzeitcode, der effizient auf der GPU ausgeführt werden kann.
WebGPU ist eine moderne Grafik-API, die Webanwendungen den direkten Zugriff auf die GPU-Leistung ermöglicht. Für WebLLM ist WebGPU der Motor, der den feinabgestimmten Code ausführt, der von Apache TVM generiert wurde. So passt es in das Bild:
- Ressourcenmanagement: WebGPU verwaltet die Zuordnung und Verwaltung von GPU-Speicher für Modellparameter, Eingabedaten und Berechnungen, um den effizienten Einsatz von Ressourcen sicherzustellen.
- Shaderausführung: Es kompiliert und führt Shader aus – kleine Programme auf der GPU – die die schweren Lasten der neuronalen Netzwerkoperationen bewältigen.
- Befehlsverarbeitung: WebGPU kodiert und übermittelt Befehle an die GPU, orchestriert die Ausführung des optimierten Codes und sorgt für einen reibungslosen Betrieb.
Im Moment ist die WebGPU-Unterstützung(neues Fenster) nicht in allen Browsern vorhanden, zumindest nicht standardmäßig. Safari hat beispielsweise erst kürzlich Unterstützung in seiner “Technology Preview”-Version hinzugefügt, und Firefox zwingt dich, ein Flag namens dom.webgpu.enabled zu aktivieren. Fast keine mobilen Browser unterstützen WebGPU, abgesehen von solchen auf Chromium-Basis. Diese Einschränkungen machen es schwierig, alle Benutzer standardmäßig zu unterstützen.
Es gibt auch andere Überlegungen neben der fehlenden WebGPU-Unterstützung, die das Ausführen von Modellen im Browser schwierig machen. Um ein Modell lokal auszuführen, musst du folgendes haben:
- Ausreichende Bandbreite: Du musst ein Modell mit mehreren GB herunterladen (größere Modelle liefern in der Regel bessere Ergebnisse).
- Eine angemessen starke GPU: Wenn du einen Mac hast, kann jede Apple M-Serie-Maschine ein 7B-Parameter-Modell ausführen. Wenn du Windows oder Linux verwendest, wird eine dedizierte GPU mit 6 GB VRAM ein LLM ausführen.
Wie du sehen kannst, ist es bereits möglich, ein personalisiertes LLM mit sicherem Zugriff auf deine personalisierten Daten auf deinem Computer oder Smartphone auszuführen – solange dein Gerät leistungsstark genug ist. Leider macht diese Anforderung viele Menschen unerschwinglich. Die meisten Modelle sind zudem prohibitively large, was es schwierig macht, sie an abgelegenen Orten oder in Ländern mit schlechter Internetinfrastruktur herunterzuladen.
Die Zukunft auf Gerät
Während die Möglichkeit, auf Device-LLMs zu laufen, derzeit auf die besten, leistungsstärksten und teuersten Geräte beschränkt ist, haben wir bereits bemerkenswerte technologische Fortschritte in den letzten zwei Jahren gesehen, um LLMs für alle verfügbar zu machen. Die Trends, die wir heute sehen, werden sich wahrscheinlich weiter in folgende Richtung bewegen:
- Lokal standardmäßig: LLMs sind teuer im Betrieb, daher macht es sowohl aus einer Datenschutz- als auch aus einer Kostenperspektive Sinn, die Generierung auf den Client auszulagern. Mehr Unterstützung für WebGPU wird es allen Benutzern erleichtern, Modelle in ihren Browsern auszuführen.
- Kleinere LLMs: Aufgabenspezifische LLMs werden verbreiteter, was es dir ermöglicht, zwischen Modellen zu wechseln, während du zwischen Aufgaben wechselst – zum Beispiel eines für E-Mails, eines für die Erstellung von Dokumenten, eines für Bilder, Audio, Suche usw. Kleinere Modelle laufen schneller und zeigen bereits, dass sie genauso gut und, in einigen Fällen besser als(neues Fenster) große Modelle wie GPT 4 bei bestimmten Aufgaben abschneiden.
- LLMs innerhalb von SDKs/Browsern: Anwendungsentwickler werden bald in der Lage sein, LLMs genau so aufzurufen, wie sie andere Funktionen in einem SDK aufrufen, wie etwa den Zugriff auf die Kamera des Benutzers in einer Android-Anwendung. Dies wird die LLM-Integration erleichtern und, wenn sie auf dem Gerät erfolgt, auch standardmäßig privat sein.
Serverseitige LLMs
Serverseitige Modelle bleiben die schnellste und zuverlässigste Methode, um LLMs auszuführen, und gewährleisten eine robuste Leistung und Stabilität.
LLMs auf deiner eigenen Maschine auszuführen, verbessert deine Privatsphäre, erfordert jedoch leistungsstarke Hardware, um die Rechenanforderungen effektiv zu verwalten.
Wir haben bereits gesehen, wie LlamaCPP verwendet werden kann, um Modelle auf Verbrauchgeräten auszuführen, aber es kann auch auf Servern verwendet werden, um die Schnittstellen zu liefern, um Modelle performant auf High-End-GPUs auszuführen. Es unterstützt die Funktionen, die zum Ausführen von LLMs in produktiveren Umgebungen mit Parallelität benötigt werden (um mehreren Benutzern gleichzeitig zu dienen), Zugriffstokens (um den Serverzugang nur denen mit Berechtigung zu gewähren), SSL (um den Datenverkehr von einem Client zum Server zu verschlüsseln) und Gesundheitsüberwachung (um sicherzustellen, dass dein System aktiv ist).
Serverseitige Modelle
Während die zuvor genannten Modelle für die Installation im Gerät auch serverseitig funktionieren können, macht es typischerweise Sinn, leistungsstärkere Modelle auszuführen, um bessere Leistung zu erhalten (wenn du sie benötigst). Wenn du dir das unten stehende Diagramm ansiehst, siehst du, wie sich Mixtral 8x22B-Modelle im Vergleich zu GPT 4 Turbo oder GPT 3.5 Turbo verhalten. Wenn du ein ChatGPT-Niveau-Modell-Performance möchtest, kannst du schon jetzt sehr nah daran kommen.
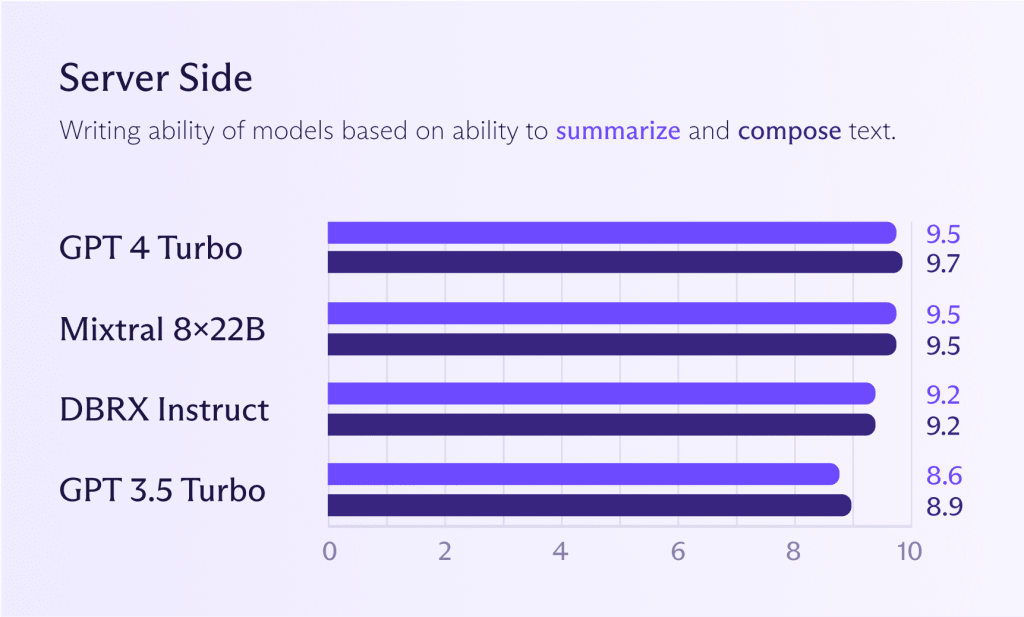
Wie bereits erwähnt, stellt sich die Frage, ob du für die meisten Aufgaben eine Leistung auf ChatGPT-Niveau benötigst. Ein großes Modell für alle Aufgaben zu verwenden, ist verschwenderisch, als würde man einen Gourmetkoch anheuern, um Kartoffeln zu kochen. Der Koch wird es machen, aber du wirst einen hohen Preis für dieses Privileg zahlen. Nur weil du kannst, bedeutet das nicht, dass du es tun solltest.
Die Zukunft der serverseitigen Inferenz
Homomorphe Verschlüsselung (HE) ist ein vielversprechender, wenn auch noch entwickelnder Ansatz, um eine datenschutzfreundliche Inferenz auf LLMs über Netzwerke zu ermöglichen.
HE ist wichtig, weil es eine leistungsstarke Möglichkeit bietet, mit verschlüsselten Daten zu arbeiten. Es ermöglicht, Berechnungen auf Ciphertexten durchzuführen, die, wenn sie entschlüsselt werden, dasselbe Ergebnis liefern wie wenn die Operationen auf dem Klartext durchgeführt worden wären. Dieses Merkmal macht HE besonders interessant für Anwendungen, die sensible Daten betreffen, einschließlich der Arbeit mit LLMs.
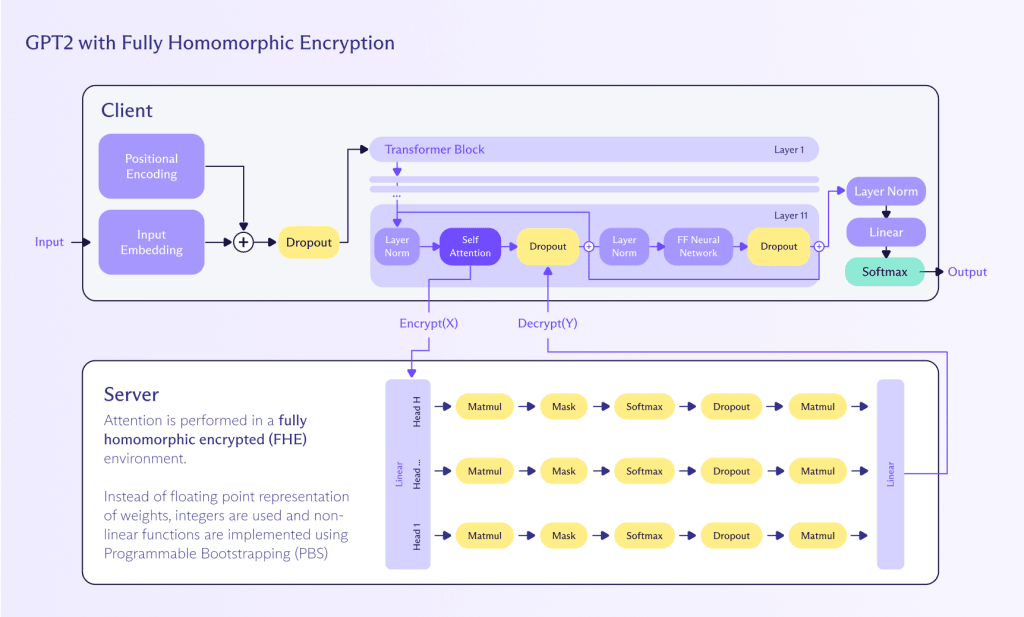
Homomorphe Berechnung ist eine Methode, um Berechnungen auf verschlüsselten Daten durchzuführen, ohne sie zuerst entschlüsseln zu müssen. Dieser Ansatz schützt die Privatsphäre und Sicherheit während des gesamten Berechnungsprozesses. So kann es angewendet werden, um Inferenz auf einem LLM durchzuführen:
- Verschlüsselung: Benutzerinput (zum Beispiel Text) wird mit einem homomorphen Verschlüsselungsschema verschlüsselt. Das sorgt dafür, dass die Eingabedaten vertraulich und sicher bleiben.
- Berechnung: Der LLM, der zur Unterstützung homomorpher Operationen angepasst wurde, verarbeitet die verschlüsselte Eingabe. Das Modell führt seine Berechnungen direkt auf den verschlüsselten Daten durch und erzeugt eine verschlüsselte Ausgabe.
- Entschlüsselung: Das vom LLM erzeugte verschlüsselte Ergebnis wird dann entschlüsselt, um die endgültige Klartextausgabe für den Benutzer bereitzustellen.
Obwohl homomorphe Verschlüsselung bereits existiert, befindet sie sich noch in der frühen Phase und kann aus mehreren Gründen noch nicht skalieren, um LLMs zu verarbeiten:
- Leistung: Homomorphe Verschlüsselung ist rechenintensiv und kann den Inferenzprozess erheblich verlangsamen. Fortschritte in Hardware und Optimierungstechniken sind erforderlich, um diesen Ansatz für Echtzeitanwendungen praktikabel zu machen.
- Modellanpassung: Bestehende LLMs müssen angepasst werden, um homomorphe Operationen zu unterstützen, was komplex sein kann und spezielles Wissen über Kryptographie und Maschinenlernen erfordert.
- Skalierbarkeit: Sicherzustellen, dass das homomorphe Verschlüsselungsschema skalieren kann, um große Modelle und große Datenmengen zu verarbeiten, ist entscheidend für die weit verbreitete Annahme.
Zama(neues Fenster) versucht beispielsweise, vollkommen homomorphe Verschlüsselung (FHE) in ML-Algorithmen zu integrieren und hat ein funktionales Beispiel(neues Fenster) dafür, wie dies mit GPT-2-Modellen gemacht werden kann, obwohl es langsam (und teuer) ist. Wie Zama erklärt(neues Fenster), gibt es einen Weg zu FHE-LLMs in den nächsten Jahren durch weitere LLM-Kompression, Verbesserungen der Kryptografie hinter FHE und dedizierte Hardwarebeschleunigung, die für 2025 erwartet wird.
Privatsphäre ist die Zukunft der KI
Generative KI ist eine potenziell generationenprägende Entwicklung — die auch die Proton-Community beschäftigt, wie in unserer Umfrage 2024 deutlich wurde. Neueste technologische Entwicklungen haben LLMs offener, kleiner und schneller gemacht, was völlig neue Möglichkeiten für GenAI eröffnet.
Heute können viele bereits einen personalisierten, vollständig privaten KI-Assistenten auf ihrem Gerät betreiben, indem sie diese LLMs mit ihren eigenen Inhalten kombinieren — etwas, das vor einigen Jahren nur im Bereich der Science-Fiction möglich war.
Die nächste Grenze besteht darin, dieses Leistungsniveau Menschen mit Verbindungs- oder Gerätebeschränkungen zugänglich zu machen. FHE scheint diese Lücke zu schließen und verschlüsselte, datenschutzfreundliche LLMs in naher Zukunft zu ermöglichen. Bis dahin werden serverseitige Modelle, die auf Hochleistungs-GPUs laufen, die schnellste Möglichkeit bleiben, Inhalte unter diesen widrigen Bedingungen zu generieren, jedoch möglicherweise auf Kosten gewisser Datenschutzebenen.
Wenn du an der Entwicklung datenschutzfreundlicher KI und verwandter Technologien arbeiten möchtest, schaue auf unserer Karriereseite nach möglichen Stellenangeboten.






