I grandi modelli linguistici (LLM) addestrati su dataset pubblici possono servire a diversi scopi, dalla composizione di post di blog alla programmazione. Tuttavia, il loro vero potenziale risiede nella contestualizzazione, ottenuta affinando il modello o arricchendo i suoi prompt con informazioni aggiuntive specifiche. Questo processo comporta tipicamente l’inserimento di dati personalizzati nel LLM, che potrebbero contenere materiali sensibili come la cronologia messaggi personali, documenti aziendali interni o comunicazioni lavorative. L’assenza di garanzie di privacy robuste in questi scenari è uno dei motivi principali per cui paesi come l’Italia ha imposto divieti(nuova finestra) su piattaforme come ChatGPT.
Gli LLM sono strumenti incredibili e abbiamo appena iniziato a scoprire ciò che possono fare. Tuttavia, come qualsiasi strumento, gli LLM possono essere abusati, in particolare per la sorveglianza. In questo articolo, mostriamo come pensiamo che debba essere il futuro dell’IA, uno in cui puoi interagire con gli LLM e sapere che le informazioni che condividi sono al sicuro.
Attualmente, hai due opzioni se vuoi eseguire un LLM:
- Localmente sul tuo dispositivo: Il LLM funziona direttamente sul tuo hardware utilizzando il tuo browser e non interagisce mai con server esterni. Questa è la forma più privata di inferenza AI poiché i tuoi dati non lasciano mai la tua macchina, ma richiede una macchina con una GPU potente a causa dei calcoli intensivi richiesti dal LLM.
- Lato server: Le tue richieste vengono inviate a server esterni, che eseguono i calcoli LLM utilizzando GPU di alta gamma. Questa istanza di IA non ha requisiti hardware specifici e può essere eseguita su quasi qualsiasi smartphone, laptop o desktop con connettività internet. Tuttavia, eseguire richieste su un server esterno aumenta i rischi di esposizione dei dati a meno che i server non siano protetti e non registrino i tuoi prompt o risposte.
Questo articolo esamina:
- Le prestazioni e l’apertura di diversi LLM e spiega quali lavori ciascun modello è più adatto a svolgere.
- Le sfide tecniche presentate da LLM su dispositivo (ad esempio, come farli funzionare localmente sul tuo dispositivo).
- Come i modelli lato server funzionano e cosa si può fare per abilitare un’elaborazione più incentrata sulla privacy lato server.
Modelli
Gli LLM sono addestrati su vasti e diversi dataset provenienti da internet, inclusi libri, articoli e siti web come Wikipedia. Questa vasta raccolta di dati garantisce che il modello apprenda le sfumature del linguaggio, inclusi sintassi, semantica e contesto.
Il processo di addestramento comporta il preprocessing dei dati tramite tokenizzazione, normalizzazione e filtraggio per garantire qualità e coerenza. Utilizzando l’architettura Transformer(nuova finestra), il modello impara prevedendo la parola successiva in una frase e apportando modifiche ai suoi parametri interni per minimizzare gli errori su milioni o miliardi di esempi. Questo processo computazionalmente intensivo richiede risorse significative che coinvolgono molte GPU potenti e giorni di addestramento.
Una tecnica avanzata per perfezionare gli LLM è l’apprendimento per rinforzo dal feedback umano(nuova finestra) (RLHF). In questo approccio, gli valutatori umani forniscono feedback sulle uscite del modello, aiutando a perfezionare le sue risposte. Il feedback viene utilizzato per addestrare un modello di ricompensa che predice la qualità delle risposte e l’LLM viene ulteriormente addestrato utilizzando tecniche di apprendimento per rinforzo guidate da questo modello di ricompensa. RLHF garantisce che le uscite del modello siano più allineate alle aspettative umane, migliorando la sua usabilità nelle applicazioni reali.
Quando un modello è addestrato, puoi quindi eseguire inferenza, in cui il modello addestrato genera previsioni o risposte basate su nuovi dati di input. Questa operazione comporta diversi passaggi, a cominciare da una versione tokenizzata del prompt di un utente. Il modello elabora il nuovo input attraverso i suoi strati della rete neurale per generare una risposta coerente e contestualmente appropriata. Il modello converte quindi i token generati di nuovo in testo leggibile da un umano.
Apertura del modello
Una delle grandi storie di successo dall’inizio di ChatGPT è stato il lavoro incredibile nella creazione di alternative aperte che chiunque può utilizzare, democratizzando così gli LLM.
Tuttavia, mentre i programmatori dovrebbero essere lodati per i loro sforzi, dobbiamo anche essere cauti riguardo al “washing aperto”, simile al “washing della privacy” o “greenwashing”, in cui le aziende dichiarano che i loro modelli sono “aperti”, ma in realtà solo una piccola parte lo è.
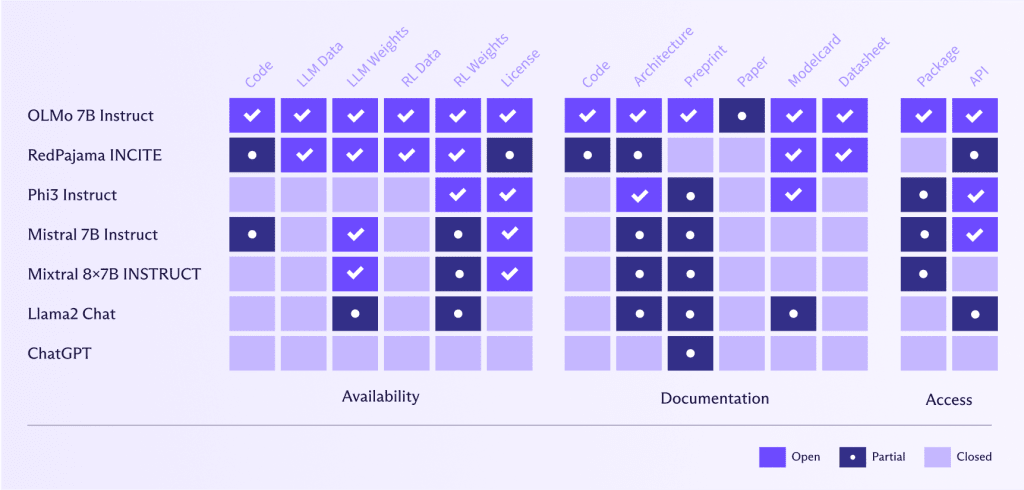
LLM aperti come OLMo 7B Instruct(nuova finestra) offrono vantaggi significativi nella valutazione, riproducibilità, trasparenza algoritmica, rilevamento dei bias e collaborazione della comunità. Consentono una rigorosa valutazione delle prestazioni e la validazione della ricerca AI, che a sua volta promuove fiducia e consente alla comunità di identificare e affrontare i bias. Gli sforzi collaborativi portano a miglioramenti e innovazioni condivisi, accelerando i progressi nell’IA. Inoltre, gli LLM aperti offrono flessibilità per soluzioni personalizzate e sperimentazione, consentendo agli utenti di personalizzare ed esplorare nuove applicazioni e metodologie.
Democratizzando l’accesso a IA avanzate, gli LLM aperti aiutano a prevenire la concentrazione delle capacità AI all’interno di poche aziende tecnologiche dominanti, promuovendo una distribuzione del potere più equilibrata.
Al contrario, Meta o OpenAI, per esempio, hanno una definizione molto diversa di “aperto” rispetto a AllenAI(nuova finestra) (l’istituto dietro OLMo 7B Instruct). Queste aziende hanno reso il loro codice, dati, pesi e articoli di ricerca solo parzialmente disponibili o non li hanno condivisi affatto.
L’apertura negli LLM è cruciale per la privacy e l’uso etico dei dati, poiché consente alle persone di verificare quali dati il modello ha utilizzato e se questi dati sono stati ottenuti in modo responsabile. Rendendo aperti gli LLM, la comunità può esaminare e verificare i dataset, garantendo che le informazioni personali siano protette e che le pratiche di raccolta dei dati rispettino standard etici. Questa trasparenza favorisce fiducia e responsabilità, essenziali per lo sviluppo di tecnologie AI che rispettano la privacy degli utenti e sostengono principi etici.
Dimensioni e prestazioni del modello
Grandi modelli
Finora, la dimensione conta quando si tratta di LLM: modelli più grandi performano meglio di modelli più piccoli per i seguenti motivi:
- Capacità di apprendere modelli complessi: Con più parametri (oltre 70 miliardi per Llama3), i modelli più grandi possono apprendere e rappresentare modelli più complessi nei dati. Questo permette loro di generare risposte più accurate e sfumate.
- Migliore generalizzazione: I modelli più grandi possono generalizzare meglio dai dati di addestramento ai dati non visti. Possono catturare una gamma più ampia di strutture linguistiche e sfumature, portando a un miglioramento delle prestazioni in vari compiti.
- Maggiore comprensione contestuale: I modelli più grandi possono mantenere e elaborare contesti più lunghi, consentendo loro di generare risposte più coerenti e contestualmente appropriate. Questo è particolarmente importante per i compiti che richiedono una comprensione di testi estesi, come la sintesi e la generazione di dialoghi.
- Migliore messa a punto: I modelli più grandi forniscono una migliore base per la messa a punto su compiti o domini specifici. Possono sfruttare la loro vasta conoscenza pre-addestrata per adattarsi più efficacemente a dataset specializzati, migliorando le prestazioni in applicazioni specifiche.
I grandi modelli, con il loro numero elevato di parametri (e quindi di pesi), occupano molta memoria e richiedono notevoli risorse CPU o GPU per eseguire l’inferenza in modo efficace. Quindi, anche se GPT4 fosse aperto, eseguirlo sarebbe comunque proibitivamente costoso.
Ci sono, tuttavia, alcuni modi per rendere i grandi modelli più piccoli senza sacrificare drammaticamente le prestazioni, inclusi:
- Quantizzazione del modello: Questo è quando grandi rappresentazioni in virgola mobile con consumo di memoria di pesi del modello vengono convertite in rappresentazioni a 8 bit o a 4 bit, consentendo agli LLM di utilizzare aritmetica a bassa precisione. Ciò riduce significativamente la memoria e i requisiti computazionali del dispositivo senza compromettere enormemente l’accuratezza del modello.
“Quantizzazione e addestramento di reti neurali per inferenza efficiente solo con aritmetica intera” di Jacob et al., 2018. “Llm. int8: moltiplicazione di matrici a 8 bit per trasformatori su larga scala” di Dettmers et al., 2022. - Potatura dei pesi: Questo comporta la rimozione di pesi meno significativi dal modello, riducendo la sua dimensione e le richieste computazionali mantenendo l’accuratezza.
“Apprendimento dei pesi e delle connessioni per reti neurali efficienti” di Han et al., 2015.
Poi, infine, c’è l’opzione per modelli più piccoli, più specializzati e meno intensivi in risorse.
Modelli più piccoli
Con un numero minore di parametri, i modelli più piccoli richiedono anche meno calcoli durante l’inferenza, rendendoli più veloci e meno intensivi in memoria e uso della GPU, aprendo la strada per eseguire gli LLM direttamente su un dispositivo consumer.
Sebbene i modelli più piccoli generalmente non performino bene quanto i modelli più grandi in base generale a causa della loro incapacità di catturare modelli più sfumati nel testo, ci sono diversi modi in cui possiamo far comportare i modelli più piccoli più simile a quelli più grandi per compiti specifici. Questi includono:
- Distillazione della conoscenza: Questo è quando un grande modello pre-addestrato (insegnante) viene utilizzato per addestrare un modello più piccolo (studente) che imita le prestazioni del modello più grande ma con meno parametri, rendendolo più adatto per l’esecuzione sul dispositivo.
“Distillare la conoscenza in una rete neurale” di Hinton, Vinyals e Dean, 2015.”DistilBERT, una versione distillata di BERT: più piccola, più veloce, più economica e più leggera” di Sanh et al., 2019. - Miscela di esperti (MoE): i modelli MoE, come Mixtral 8x7B, migliorano le prestazioni combinando più modelli specializzati e più piccoli (esperti), ciascuno concentrandosi su diversi aspetti dei dati di input (ad esempio, un modello per la punteggiatura, uno per i verbi, un altro per i numeri, ecc.). Un meccanismo di gating seleziona dinamicamente gli esperti più rilevanti per ciascun input, assicurando che solo un sottoinsieme sia attivato, riducendo i costi computazionali e migliorando l’efficienza. Questo approccio consente ai modelli MoE di specializzarsi e scalare in modo efficace mantenendo alta accuratezza e robustezza in vari compiti senza aumenti proporzionali nelle richieste computazionali.
Modelli come Mixtral 8x7B Instruct superano modelli come Llama2, con i suoi 70 miliardi di parametri, in termini di capacità di generare contenuti coerenti, ma sono anche sei volte più veloci nell’elaborazione.
Per modelli molto grandi, i modelli Mixtral 8x22B possono concorrere o addirittura superare GPT4 e GPT3.5. Dato che GPT4 usa 1,76 trilioni di parametri, è impressionante che un modello con un ordine di grandezza in meno possa avere prestazioni simili.
LLM su dispositivo
La natura aperta dei modelli e gli sviluppi successivi da parte di ricercatori e ingegneri hanno portato a LLM che possono girare su un dispositivo dell’utente senza un drastico calo di precisione o velocità.
LLM su dispositivo possono offrire potenti capacità AI preservando la privacy dell’utente e quindi funzionare in modalità E2EE. Alcuni progetti open-source, in particolare Llamacpp(nuova finestra) e WebLLM(nuova finestra), rendono più facile eseguire LLM localmente.
Llamacpp(nuova finestra) è una libreria C++ open-source che permette di eseguire la tua API compatibile con OpenAI su LLM sul tuo computer (o server) utilizzando CPU o GPU. Una delle tecniche chiave di ottimizzazione usate in llama.cpp è la quantizzazione, che riduce significativamente l’uso della memoria e accelera l’elaborazione senza grandi compromessi sulla precisione.
Llamacpp richiede che i modelli siano caricati nel formato unificato generato da GPT (GGUF), un formato binario personalizzato che memorizza efficientemente i parametri del modello di machine learning. È progettato per ottimizzare l’archiviazione e l’accesso ai pesi del modello, in particolare per scenari in cui i modelli devono essere caricati rapidamente e utilizzati in ambienti con vincoli di memoria.
Il progetto WebLLM(nuova finestra) consente di eseguire LLM direttamente nel tuo browser web. WebLLM sfrutta la potenza di WebGPU(nuova finestra) e la capacità di ottimizzazione di Apache TVM(nuova finestra).
Apache TVM è un compilatore di machine learning open-source che gioca un ruolo cruciale nel rendere WebLLM possibile usando:
- Trasformazione del modello: I modelli creati in framework ad alto livello come TensorFlow o PyTorch vengono importati in TVM. TVM poi converte questi modelli in una rappresentazione intermedia (IR) che può essere ottimizzata per prestazioni.
- Ottimizzazione: TVM esegue una serie di ottimizzazioni sofisticate su questo IR. Unisce operazioni per ridurre l’accesso ridondante alla memoria, pianifica l’uso della memoria in modo efficiente e ristruttura i grafi di computazione per massimizzare il parallelismo. Questo passaggio è chiave per far funzionare i modelli in modo rapido e leggero sulla GPU del tuo browser.
- Generazione di codice: Una volta ottimizzato, TVM genera codice su misura per WebGPU. Questo comporta la compilazione dei kernel e la creazione di codice di runtime che può essere eseguito in modo efficiente sulla GPU.
WebGPU è un’API grafica moderna progettata per dare alle applicazioni web accesso diretto alla potenza della GPU. Per WebLLM, WebGPU è il motore che esegue il codice ottimizzato generato da Apache TVM. Ecco come si integra:
- Gestione delle risorse: WebGPU gestisce l’allocazione e la gestione della memoria GPU per i parametri del modello, i dati di input e i calcoli, garantendo un uso efficiente delle risorse.
- Esecuzione dello shader: Compila ed esegue shader — piccoli programmi sulla GPU — che svolgono il lavoro pesante delle operazioni delle reti neurali.
- Gestione dei comandi: WebGPU codifica e invia comandi alla GPU, orchestrando l’esecuzione del codice ottimizzato e garantendo un’operazione fluida.
Al momento, il supporto per WebGPU(nuova finestra) non è presente in tutti i browser, almeno non di default. Safari, ad esempio, ha appena aggiunto supporto nella sua versione “Technology Preview”, e Firefox richiede di abilitare una flag chiamata dom.webgpu.enabled. Praticamente nessun browser mobile, a parte quelli basati su Chromium, supporta WebGPU. Queste avvertenze rendono difficile supportare tutti gli utenti di default.
Ci sono anche altre considerazioni oltre alla mancanza di supporto per WebGPU che rendono difficile eseguire modelli nel browser. Per eseguire un modello localmente, devi avere:
- Larghezza di banda sufficiente: Devi scaricare un modello da più GB (ancora, modelli più grandi di solito producono risultati migliori).
- Una GPU ragionevolmente potente: Se hai un Mac, qualsiasi macchina della serie M di Apple può eseguire un modello con 7B di parametri. Se usi Windows o Linux, una GPU dedicata con 6 GB di VRAM eseguirà un LLM.
Come puoi vedere, è già possibile eseguire un LLM personalizzato con accesso sicuro ai tuoi dati personalizzati sul tuo computer o smartphone — purché il tuo dispositivo sia abbastanza potente. Sfortunatamente, questa esigenza esclude molte persone. La maggior parte dei modelli sono anche proibitivamente grandi, rendendo difficile scaricarli in luoghi remoti o in paesi con infrastrutture internet deboli.
Il futuro dei dispositivi
Mentre la possibilità di eseguire LLM su dispositivo è attualmente limitata ai dispositivi migliori, più potenti e costosi, abbiamo già visto notevoli progressi tecnologici negli ultimi due anni verso la disponibilità degli LLM per tutti. Le tendenze che vediamo oggi continueranno probabilmente a muoversi verso:
- Locale per default: LLM sono costosi da eseguire, quindi scaricare la generazione sul cliente ha senso sia per la privacy che per i costi. Maggiore supporto per WebGPU renderà più facile per tutti gli utenti eseguire modelli nei loro browser.
- LLM più piccoli: LLM specifici per compito diventeranno più comuni, permettendoti di passare tra modelli mentre cambi compito — per esempio, uno per email, uno per creazione di documenti, uno per immagini, audio, ricerca, e così via. Modelli più piccoli girano più velocemente e già dimostrano prestazioni pari e, in alcuni casi, superiori a(nuova finestra) modelli grandi come GPT 4 su compiti specifici.
- LLM all’interno di SDK/browsers: Gli sviluppatori di applicazioni potranno presto chiamare LLM come fanno con altre funzionalità in un SDK, come accedere alla fotocamera dell’utente in un’applicazione Android. Questo renderà più semplice l’integrazione degli LLM e, se gestita sul dispositivo, privata per default.
LLM sul server
I modelli sul server rimangono il metodo più veloce e affidabile per eseguire LLM, garantendo prestazioni robuste e stabilità.
Eseguire LLM sulla tua macchina migliora la tua privacy ma richiede hardware potente per gestire efficacemente le esigenze di calcolo.
Abbiamo già visto come LlamaCPP può essere usato per eseguire modelli su dispositivi consumer, ma può anche essere utilizzato su server, fornendo le interfacce per eseguire i modelli in modo prestante su GPU di fascia alta. Ha supporto per le funzionalità necessarie per eseguire LLM in ambienti a livello di produzione con parallelismo (per servire più utenti contemporaneamente), token di accesso (per fornire accesso al server solo a chi ha permesso), SSL (per crittografare il traffico da client a server) e monitoraggio dello stato (per garantire che il tuo sistema sia attivo).
Modelli sul server
Sebbene i modelli menzionati in precedenza per il dispositivo possano funzionare anche sul server, di solito ha senso eseguire modelli più potenti per ottenere prestazioni migliori (se necessario). Guardando il grafico qui sotto, vedrai come i modelli Mixtral 8x22B si confrontano con GPT 4 Turbo o GPT 3.5 Turbo. Se desideri prestazioni simili a ChatGPT, puoi già arrivare molto vicino.
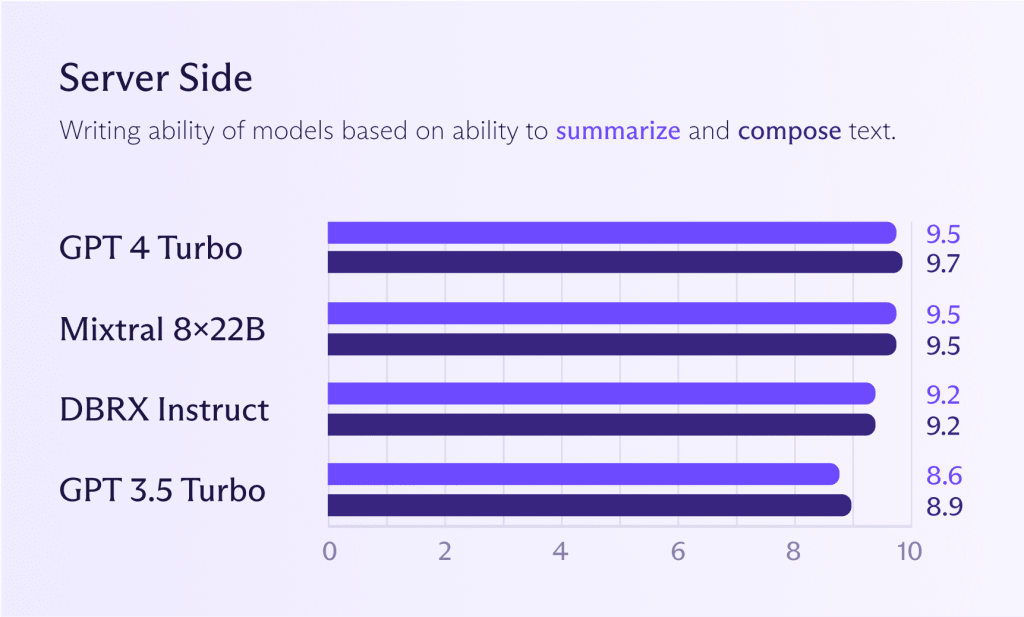
Tuttavia, come già detto, è discutibile se hai bisogno delle prestazioni di ChatGPT per la maggior parte dei compiti. Usare un grande modello per tutti i compiti è uno spreco, come assumere un maestro gourmet per bollire le patate. Il cuoco lo farà, ma pagherai un prezzo elevato per il privilegio. Solo perché puoi non significa che dovresti.
Il futuro dell’inferenza sul server
La crittografia omomorfica (HE) è un approccio promettente, anche se ancora in sviluppo, per abilitare l’inferenza che preserva la privacy su LLM attraverso le reti.
HE è importante perché offre un modo potente di lavorare con i dati crittografati. Permette di eseguire calcoli su dati crittografati che, una volta decifrati, producono lo stesso risultato di se le operazioni fossero state eseguite su dati in chiaro. Questa caratteristica rende HE particolarmente intrigante per le applicazioni che coinvolgono dati sensibili, comprese le operazioni con LLM.
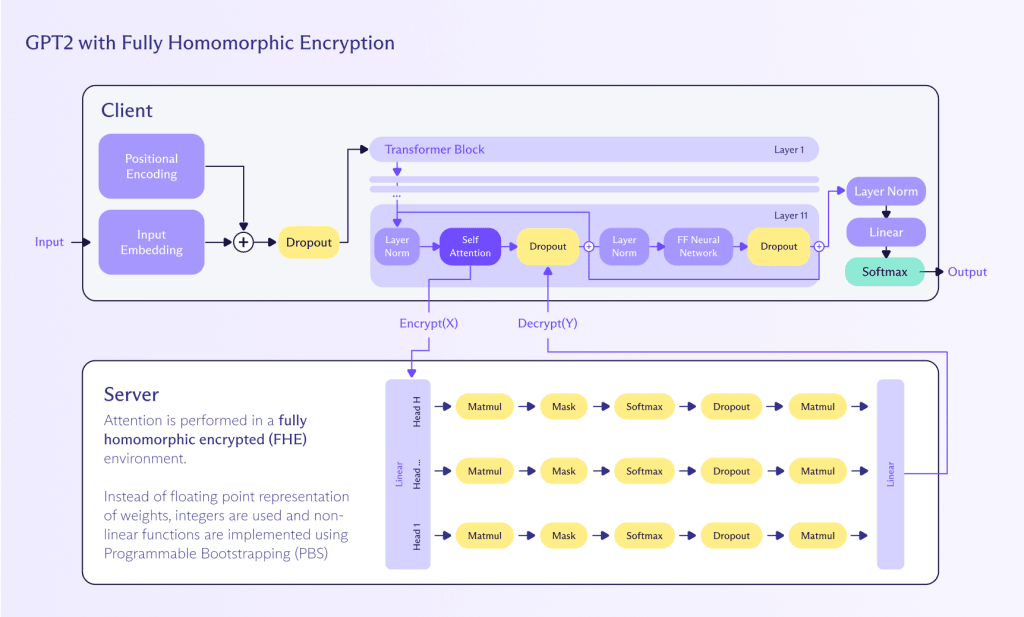
Il calcolo omomorfico è un metodo per eseguire calcoli su dati crittografati senza necessità di decifrarli prima. Questo approccio preserva la privacy e la sicurezza per tutto il processo di calcolo. Ecco come può essere applicato per eseguire inferenza su un LLM:
- Crittografia: L’input dell’utente (per esempio, testo) è crittografato utilizzando uno schema di crittografia omomorfica. Questo garantisce che i dati di input rimangano riservati e sicuri.
- Calcolo: Il LLM, che è stato adattato per supportare operazioni omomorfiche, elabora l’input crittografato. Il modello esegue i propri calcoli direttamente sui dati crittografati, generando un output crittografato.
- Decifratura: Il risultato crittografato prodotto dal LLM viene poi decifrato per fornire il risultato finale in chiaro all’utente.
Sebbene l’**encryption** omomorfica esista già, è ancora nelle sue fasi iniziali e non può ancora scalare per gestire gli LLM per diversi motivi:
- Prestazioni: L’**encryption** omomorfica è computazionalmente intensiva e può rallentare significativamente il processo di inferenza. Sono necessari progressi nell’hardware e nelle tecniche di ottimizzazione per rendere questo approccio pratico per le applicazioni in tempo reale.
- Adattamento del modello: Gli LLM esistenti devono essere adattati per supportare le operazioni omomorfiche, il che può essere complesso e richiede conoscenze specializzate sia in crittografia che in machine learning.
- Scalabilità: Assicurarsi che lo schema di **encryption** omomorfica possa scalare per gestire modelli grandi e volumi di dati ampi è cruciale per un’adozione diffusa.
Zama(nuova finestra), ad esempio, sta cercando di integrare completamente l’**encryption** omomorfica (FHE) negli algoritmi di ML e ha un esempio funzionale(nuova finestra) di come fare questo con i modelli GPT-2, anche se lentamente (e a caro prezzo). Tuttavia, come Zama spiega(nuova finestra), c’è un percorso avanti per gli LLM FHE nei prossimi anni attraverso una maggiore compressione degli LLM, miglioramenti alla crittografia dietro FHE e accelerazione hardware dedicata prevista per il 2025.
La privacy è il futuro dell’IA
L’IA generativa è potenzialmente uno sviluppo che definisce una generazione — uno che è presente nella mente della comunità Proton, come è stato evidente nel nostro sondaggio 2024. Recenti sviluppi tecnologici hanno reso gli LLM più aperti, più piccoli e più veloci, aprendo nuove possibilità per il GenAI.
Oggi, molte persone possono già eseguire un assistente AI personalizzato e completamente privato sul proprio dispositivo combinando questi LLM con i propri contenuti — qualcosa che era possibile solo nel regno della fantascienza qualche anno fa.
La prossima frontiera è portare questo livello di prestazioni a persone con limitazioni di connettività o dispositivi. L’FHE sembra poter colmare questo divario, consentendo LLM crittografati e rispettosi della privacy nel prossimo futuro. Fino ad allora, i modelli lato server eseguiti su GPU ad alte prestazioni rimarranno il modo più veloce per generare contenuti in queste condizioni avverse, ma a costo di alcuni livelli di privacy.
Se vuoi lavorare per costruire AI che protegge la privacy e tecnologie correlate, dai un’occhiata alla nostra pagina delle carriere per eventuali opportunità.






