
Large language models (LLMs) trained on public datasets can serve a wide range of purposes, from composing blog posts to programming. However, their true potential lies in contextualization, achieved by either fine-tuning the model or enriching its prompts with specific additional information. This process typically involves inputting custom data into the LLM, which might contain sensitive material such as personal messaging history, internal company documents, or workplace communications. The absence of robust AI privacy safeguards in these scenarios is one of the primary reasons why countries like Italy have imposed bans(new window) on platforms like ChatGPT.
LLMs are incredible tools, and we’ve only begun to scratch the surface of what they can do. However, like any tool, LLMs can be abused, particularly for surveillance. In this article, we show what we think the future of AI should look like, one where you can interact with LLMs and know the information you share is safe.
Currently, you have two options if you want to run an LLM:
- Locally on your device: The LLM runs directly on your hardware using your browser and never interacts with external servers. This is the most private form of AI inference since your data never exits your machine, but it requires a machine with a powerful GPU due to the intensive calculations required by the LLM.
- Server side: Your requests are sent to external servers, which perform the LLM calculations using high-end GPUs. This AI instance has no specific hardware requirements and can be run on almost any smartphone, laptop, or desktop with internet connectivity. However, running requests on an external server increases data exposure risks unless the servers are secured and do not log your prompts or responses.
This article looks at:
- The performance and openness of different LLMs, and explains which jobs each model is best suited to perform.
- The technical challenges presented by on-device LLMs (for example, how to get them to run locally on your device).
- How Server-side models work, and what can be done to enable more privacy-centric server-side processing.
Models
LLMs are trained on vast, diverse datasets sourced from the internet, including books, articles, and websites such as Wikipedia. This extensive data collection ensures the model learns the nuances of language, including syntax, semantics, and context.
The training process involves preprocessing the data through tokenization, normalization, and filtering to ensure quality and consistency. Using Transformer architecture(new window), the model learns by predicting the next word in a sentence and adjusting its internal parameters to minimize errors over millions or billions of examples. This computationally intensive process requires significant resources involving many powerful GPUs and days of training.
One advanced technique to refine LLMs is Reinforcement Learning from Human Feedback(new window) (RLHF). In this approach, human evaluators provide feedback on the model’s outputs, helping to fine-tune its responses. The feedback is used to train a reward model that predicts the quality of responses, and the LLM is further trained using reinforcement learning techniques guided by this reward model. RLHF ensures that the model’s outputs align more closely with human expectations, improving its usability in real-world applications.
When a model is trained, you can then perform inference, where the trained model generates predictions or responses based on new input data. This operation involves several steps, starting with a tokenized version of a user’s prompt. The model processes new input through its neural network layers to generate a coherent and contextually appropriate response. The model then converts the generated tokens back into human-readable text.
Model openness
One of the great success stories since the onset of ChatGPT has been the incredible work in creating open alternatives that anyone can use, thus democratizing LLMs.
However, whilst developers should be praised for their efforts, we should also be wary of “open washing”, akin to “privacy washing” or “greenwashing”, where companies say that their models are “open”, but actually only a small part is.
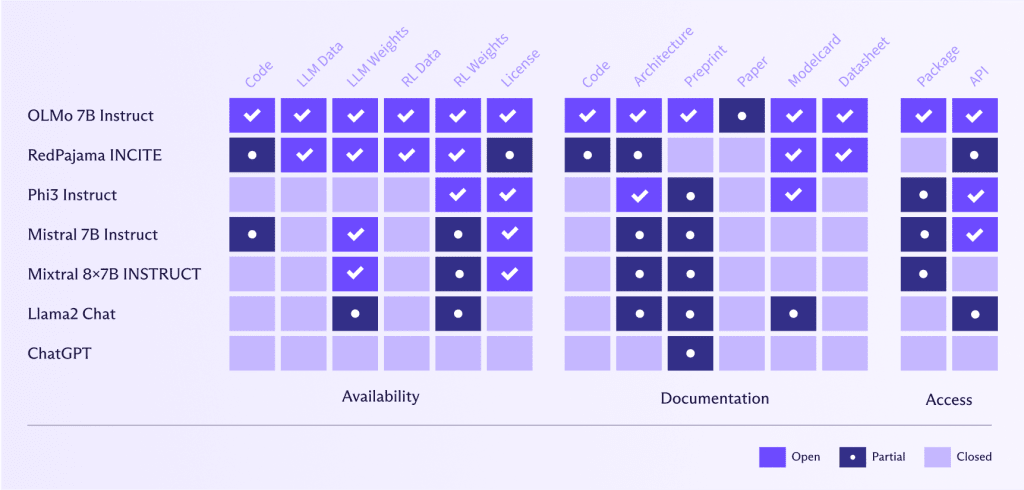
Open LLMs like OLMo 7B Instruct(new window) provide significant advantages in benchmarking, reproducibility, algorithmic transparency, bias detection, and community collaboration. They allow for rigorous performance evaluation and validation of AI research, which in turn promotes trust and enables the community to identify and address biases. Collaborative efforts lead to shared improvements and innovations, accelerating advancements in AI. Additionally, open LLMs offer flexibility for tailored solutions and experimentation, allowing users to customize and explore novel applications and methodologies.
By democratizing access to advanced AI, open LLMs help prevent the concentration of AI capabilities within a few dominant tech companies, promoting a more balanced distribution of power.
Conversely, Meta or OpenAI, for example, have a very different definition of “open” to AllenAI(new window) (the institute behind OLMo 7B Instruct). These companies have made their code, data, weights, and research papers only partially available or haven’t shared them at all.
Openness in LLMs is crucial for privacy and ethical data use, as it allows people to verify what data the model utilized and if this data was sourced responsibly. By making LLMs open, the community can scrutinize and verify the datasets, guaranteeing that personal information is protected and that data collection practices adhere to ethical standards. This transparency fosters trust and accountability, essential for developing AI technologies that respect user privacy and uphold ethical principles.
Model size and performance
Large models
So far, size matters when it comes to LLMs — bigger models perform better than smaller models for the following reasons:
- Capacity to learn complex patterns: With more parameters (over 70 billion for Llama3), larger models can learn and represent more complex patterns in the data. This allows them to generate more accurate and nuanced responses.
- Better generalization: Larger models can generalize better from training data to unseen data. They can capture a broader range of linguistic structures and nuances, leading to improved performance across various tasks.
- Higher contextual understanding: Larger models can maintain and process longer contexts, enabling them to generate more coherent and contextually appropriate responses. This is particularly important for tasks that require an understanding of extended text, such as summarization and dialogue generation.
- Improved fine-tuning: Larger models provide a better foundation for fine-tuning on specific tasks or domains. They can leverage their extensive pre-trained knowledge to adapt more effectively to specialized datasets, enhancing performance in specific applications.
Large models, with their large number of parameters (and therefore weights), take up a lot of memory and require considerable CPU or GPU resources to perform inference effectively. So even if GPT4 was open, running it would still be prohibitively expensive.
There are, however, some ways to make large models smaller without dramatically sacrificing performance, including:
- Model quantization: This is when large, memory-hungry, floating-point representations of model weights are converted to 8-bit or 4-bit representations, allowing LLMs to use lower-precision arithmetic. This significantly reduces the device’s memory and computational requirements without greatly sacrificing the model’s accuracy.
“Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference” by Jacob et al., 2018.“ Llm. int8: 8-bit matrix multiplication for transformers at scale” by Dettmers et al., 2022. - Weight pruning: This involves removing less significant weights from the model, reducing its size and computational demands while maintaining accuracy.
“Learning both Weights and Connections for Efficient Neural Networks” by Han et al., 2015.
Then, finally, there is the option for smaller, more specialized, less resource-intensive models.
Smaller models
With a smaller number of parameters, smaller models also require fewer calculations at inference time, making them faster and less resource intensive in terms of memory and GPU usage, opening the door to running LLMs directly on a consumer device.
While smaller models typically don’t perform as well as larger models on a general basis due to their inability to capture more nuanced patterns in text, there are several ways we can make smaller models behave more like larger ones for specific tasks. These include:
- Knowledge distillation: This is when a large, pre-trained model (teacher) is used to train a smaller model (student) that mimics the performance of the larger model but with fewer parameters, making it more suitable for on-device execution.
“Distilling the Knowledge in a Neural Network” by Hinton, Vinyals, and Dean, 2015.”DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter” by Sanh et al., 2019. - Mixture of Experts (MoE): MoE models, like Mixtral 8x7B, enhance performance by combining multiple specialized, smaller models (experts), each focusing on different aspects of the input data (for example, one model for punctuation, one for verbs, another form numbers, etc.). A gating mechanism dynamically selects the most relevant experts for each input, ensuring only a subset is activated, reducing computational costs and improving efficiency. This approach allows MoE models to specialize and scale effectively while providing high accuracy and robustness across diverse tasks without proportional increases in computational demands.
Models like Mixtral 8x7B Instruct outperform models like Llama2, with its 70 billion parameters, in terms of their ability to generate coherent content, but are also six times faster to perform inference on.
For very large models, Mixtral 8x22B models can perform on par or even better than GPT4 and GPT3.5. Given that GPT4 uses a reported 1.76 trillion parameters, it’s impressive that a model with an order of magnitude fewer parameters can perform similarly.
On-device LLMs
The open nature of models and subsequent developments by researchers and engineers have led to LLMs that can run on a user device without a dramatic dip in accuracy or speed.
On-device LLMs can deliver powerful AI capabilities while preserving user privacy and thus work within E2EE settings. A few open-source projects, most notably Llamacpp(new window) and WebLLM(new window), make it easier to run LLMs locally.
Llamacpp(new window) is an open-source C++ library that allows you to run your own OpenAI-compatible API on top of an LLM on your machine (or server) utilizing CPUs or GPUs. One of the key optimization techniques used in llama.cpp is quantization, which significantly reduces the memory footprint and speeds up inference without large sacrifices on accuracy.
Llamacpp requires models to be loaded from the GPT-Generated Unified Format (GGUF), a custom binary format that efficiently stores machine-learning model parameters. It’s designed to optimize the storage and access of model weights, particularly for scenarios where models need to be loaded quickly and used in memory-constrained environments.
The WebLLM(new window) project allows you to run LLMs directly in your web browser. WebLLM leverages the power of WebGPU(new window) and the optimization prowess of Apache TVM(new window).
Apache TVM is an open-source machine learning compiler that plays a crucial role in making WebLLM possible using:
- Model transformation: Models crafted in high-level frameworks like TensorFlow or PyTorch are imported into TVM. TVM then converts these models into an intermediate representation (IR) that can be fine-tuned for performance.
- Optimization: TVM performs a series of sophisticated optimizations on this IR. It fuses operations to reduce redundant memory access, plans memory usage efficiently, and restructures computation graphs for maximum parallelism. This step is key to making models run fast and lean on your browser’s GPU.
- Code Generation: Once optimized, TVM generates code tailored for WebGPU. This involves compiling kernels and creating runtime code that can execute efficiently on the GPU.
WebGPU is a modern graphics API designed to give web applications direct access to GPU power. For WebLLM, WebGPU is the engine that runs the finely tuned code generated by Apache TVM. Here’s how it fits into the picture:
- Resource management: WebGPU handles the allocation and management of GPU memory for model parameters, input data, and computations, ensuring the efficient use of resources.
- Shader execution: It compiles and runs shaders — small programs on the GPU — that carry out the heavy lifting of neural network operations.
- Command Handling: WebGPU encodes and submits commands to the GPU, orchestrating the execution of the optimized code and ensuring smooth operation.
At this moment, WebGPU support(new window) isn’t present across all browsers, at least not by default. Safari, for example, has only recently added support in its “Technology Preview” version, and Firefox makes you enable a flag called dom.webgpu.enabled. Practically no mobile browsers, apart from Chromium-based ones, support WebGPU. These caveats make it difficult to support all users by default.
There are also other considerations besides the lack of WebGPU support that make in-browser models difficult to run. To run a model locally, you must have:
- Sufficient bandwidth: You must download a multi-GB model (again, larger models will typically yield better results).
- A reasonably powerful GPU: If you have a Mac, any Apple M series machine can run a 7B parameter model. If you use Windows or Linux, a dedicated GPU with 6 GB VRAM will run an LLM.
As you can see, it’s already possible to run a personalized LLM with secure access to your personalized data on your computer or smartphone — as long as your device is powerful enough. Unfortunately, this requirement prices out many people. Most models are also prohibitively large, making it difficult to download them in remote locations or in countries with poor internet infrastructure.
The future of on-device
While the ability to run on-device LLMs is currently limited to the best, most powerful, and most expensive devices, we’ve already seen remarkable technological progress over the past two years towards making LLMs available to everyone. The trends we see today will likely continue to move towards:
- Local by default: LLMs are expensive to run, so off-loading generation to the client makes sense both from a privacy and cost perspective. More support for WebGPU will make it easier for all users to run models in their browsers.
- Smaller LLMs: task-specific LLMs will become more common, allowing you to switch between models as you switch between tasks — for example, one for email, one for document creation, one for image, audio, search, and so on. Smaller models run faster and are already shown to perform as well as, and, in some cases, better than(new window) large models such as GPT 4 on specific tasks.
- LLMs within SDKs/browsers: Application developers will soon be able to call LLMs much like they call other features in an SDK, such as getting access to the user’s camera in an Android application. This will make LLM integration easier and, if handled on-device, private by default as well.
Server-side LLMs
Server-side models remain the fastest and most reliable method for running LLMs, ensuring robust performance and stability.
Running LLMs on your own machine enhances your privacy but requires powerful hardware to effectively manage the computational demands.
We have already seen how LlamaCPP can be used to run models on consumer devices, but it can also be used on servers, providing the interfaces to run models performantly on high-end GPUs. It has support for the functionalities required to run LLMs in more production-level environments with parallelism (to serve multiple users at the same time), access tokens (to provide server access only to those with permission), SSL (to encrypt traffic from a client to server), and health monitoring (to ensure your system is alive).
Server-side models
While the models mentioned earlier for on-device can also work server side, it typically makes sense to run more powerful models to get better performance (should you need it). Looking at the graph below, you will see how Mixtral 8x22B models compare with GPT 4 Turbo or GPT 3.5 Turbo. If you want ChatGPT-level model performance, you can already get very close to it.
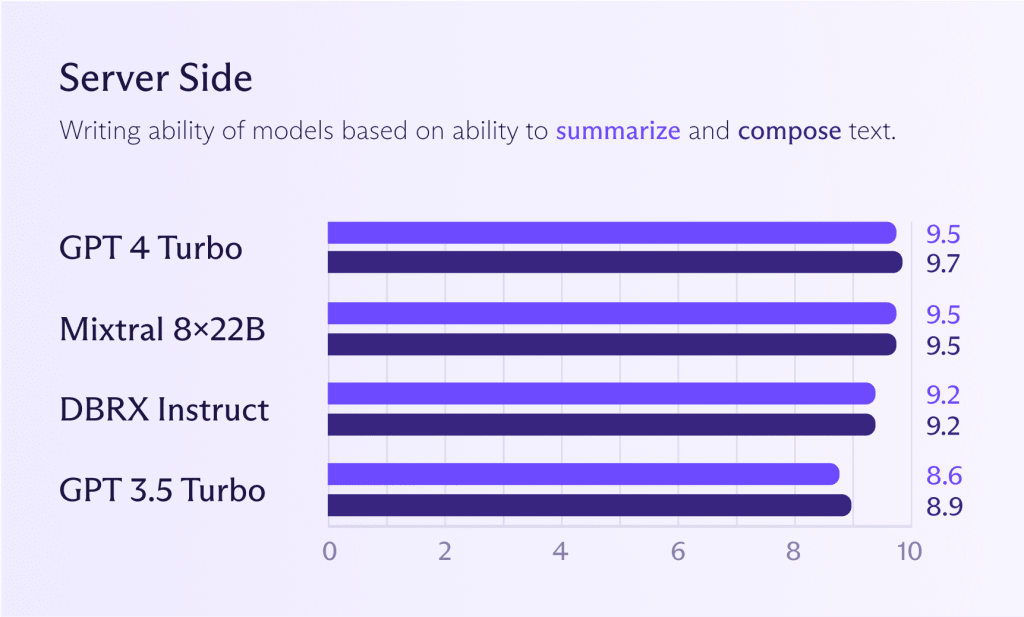
However, as stated before, it’s debatable whether you need ChatGPT-level performance for most tasks. Using one large model for all tasks is wasteful, like hiring a gourmet chef to boil potatoes. The chef will do it, but you’ll pay a hefty price for the privilege. Just because you can doesn’t mean you should.
The future of server-side inference
Homomorphic encryption (HE) is a promising, albeit still developing, approach to enable privacy-preserving inference on LLMs across networks.
HE is important because it offers a powerful way to work with encrypted data. It allows computations to be performed on ciphertext that, when decrypted, yield the same result as if the operations had been performed on the plaintext. This characteristic makes HE particularly intriguing for applications involving sensitive data, including working with LLMs.
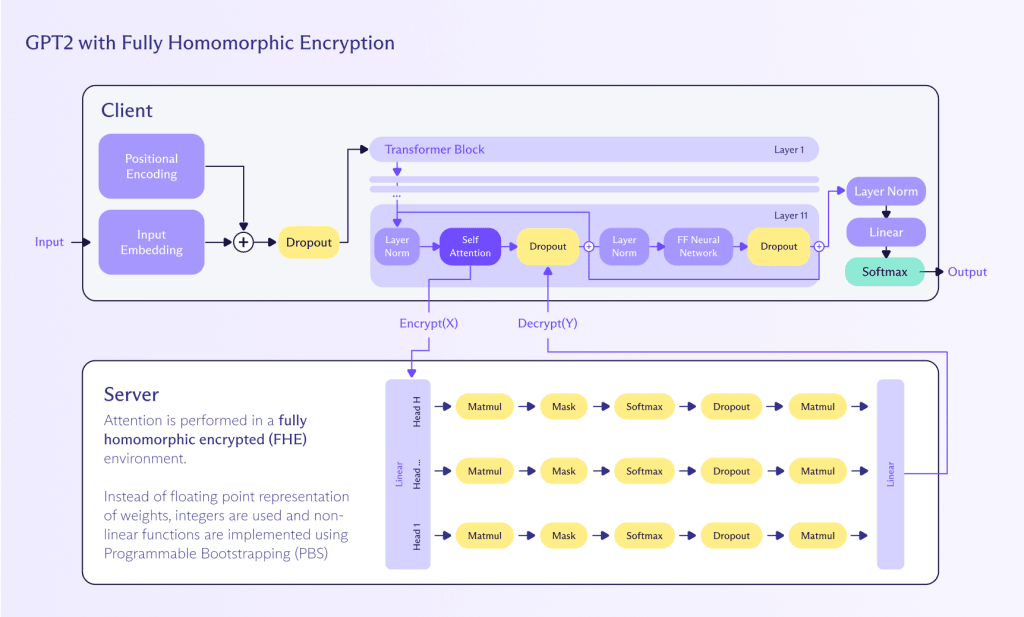
Homomorphic computing is a method of performing computations on encrypted data without needing to decrypt it first. This approach preserves privacy and security throughout the computational process. Here’s how it can be applied to perform inference on a LLM:
- Encryption: User input (for example, text) is encrypted using a homomorphic encryption scheme. This ensures that the input data remains confidential and secure.
- Computation: The LLM, which has been adapted to support homomorphic operations, processes the encrypted input. The model performs its calculations directly on the encrypted data, generating an encrypted output.
- Decryption: The encrypted result produced by the LLM is then decrypted to provide the final plaintext output to the user.
While homomorphic encryption already exists, it’s still in its early stages and can’t yet scale to handle LLMs for a number of reasons:
- Performance: Homomorphic encryption is computationally intensive and can significantly slow down the inference process. Advances in hardware and optimization techniques are needed to make this approach practical for real-time applications.
- Model adaptation: Existing LLMs need to be adapted to support homomorphic operations, which can be complex and require specialized knowledge in both cryptography and machine learning.
- Scalability: Ensuring that the homomorphic encryption scheme can scale to handle large models and large volumes of data is crucial for widespread adoption.
Zama(new window), for example, is trying to build fully homomorphic encryption (FHE) into ML algorithms and has a functional example(new window) of how to do this with GPT-2 models, although slowly (and expensively). However, as Zama explains(new window), there is a path forward to FHE LLMs in the next few years through further LLM compression, improvements to the cryptography behind FHE, and dedicated hardware acceleration predicted to arrive in 2025.
Privacy is the future of AI
Generative AI is potentially a generation-defining development — one that’s on the mind of the Proton community, as was made evident in our 2024 survey. Recent technological developments have made LLMs more open, smaller, and faster, opening entirely new possibilities for GenAI.
Today, many people can already run a personalized, fully private AI assistant on their device by combining these LLMs with your own content — something that was only possible in the realm of science fiction a handful of years ago.
The next frontier is bringing this level of performance to people with connectivity or device limitations. FHE seems like it could bridge this gap, allowing for encrypted, privacy-respecting LLMs in the not-so-distant future. Until then, server-side models running on high-performance GPUs will remain the fastest way to generate content under these adverse conditions, but at the possible cost of some levels of privacy.
If you want to work on building privacy protecting AI (new window)and related technologies, check out our careers page for potential openings.





