
Kryptographie ist das Herzstück all unserer Dienste. Das bietet enorme Vorteile, denn es liefert alle notwendigen Werkzeuge und Konstruktionen, um Funktionen mit eingebauter Sicherheit und Privatsphäre zu entwickeln. Gelegentlich können diese Schutzschichten jedoch grundlegende Funktionen behindern, an die jeder von nicht auf Privatsphäre ausgerichteten Diensten gewöhnt ist. Ein Beispiel ist der Wunsch der Proton-Community, in der Lage zu sein, den Inhalt ihrer E-Mails in der Proton Mail-App zu durchsuchen.
Das Dilemma ist so einfach zu erklären, wie es schwierig zu lösen ist. Bei Proton speichern wir alle Nachrichten in verschlüsseltem Zustand auf unseren Servern, sodass nur der Besitzer des legitimen kryptografischen Schlüssels darauf zugreifen kann. Da Proton-Server keinen Zugriff auf die Schlüssel haben, können wir deine E-Mails nicht entschlüsseln, was bedeutet, dass wir ihren Inhalt nicht durchsuchen können. Andererseits können Proton-Web- und Mobil-Apps auf entschlüsselte Nachrichten zugreifen, haben jedoch in der Regel keinen vollständigen Überblick über das gesamte Postfach, da sie Nachrichten nur dann abrufen, wenn der Nutzer mit ihnen interagiert.
Anders ausgedrückt, lässt sich das Problem wie folgt darstellen: Wie können wir den Inhalt von E-Mails durchsuchen und dabei die gewohnten Sicherheits- und Privatsphäre-Garantien beibehalten, die Proton immer geboten hat?
Unser Sicherheitsmodell für die Suche
Bevor wir uns mit konkreten Implementierungsdetails befassen, ist es wichtig, die Ziele im Blick zu behalten, die wir für die Lösung hinsichtlich der Sicherheit und Privatsphäre festgelegt haben. Bei Proton ist das Sicherheitsmodell der Hauptfaktor für alle Designentscheidungen und technischen Entscheidungen. Die Inhaltsuche der Nachrichten durfte das Datenschutzangebot, das Proton Mail(neues Fenster) bietet, nicht grundlegend verändern. Die folgende Liste bietet einen Überblick über einige Datenschutzbedenken im Zusammenhang mit der Suche nach Nachrichteninhalten und wie wir sie angesprochen haben.
- Beim Suchen sollten wir die Anfrage nicht preisgeben.
- Beim Suchen sollten wir das Ergebnisset nicht preisgeben.
- Der Server sollte keine Suche durchführen können.
- Der Server sollte den Inhalt von E-Mails nicht erfahren können.
- Wenn das lokale Gerät nach dem Herunterfahren kompromittiert wird, sollte ein Angreifer weder den Inhalt noch die Metadaten von E-Mails erfahren können.
Das sind die Kriterien, die wir immer im Kopf hatten, als wir unsere möglichen Lösungen bewertet haben.
Durchsuchbare Verschlüsselung – eine theoretisch optimale Lösung
Das Gebiet der Kryptographie ist voll von Konstruktionen, die weit über das Erreichen der grundlegendsten Sicherheitsbegriffe (d. h. Authentizität, Vertraulichkeit und Integrität von Daten) hinausgehen und erweiterte Funktionalitäten bieten, um mit den Daten zu arbeiten, ohne zu viel Privatsphäre zu opfern. Mit anderen Worten, es wurden mehrere Algorithmen entwickelt, die es ermöglichen, Funktionen auf Chiffretexten anzuwenden und dabei die Vertraulichkeit bei der Durchführung von Berechnungen zu wahren. Diese kryptografischen Schemata werden als durchsuchbare Verschlüsselung (SE) bezeichnet, wenn sie eine Suchfunktion auf Chiffretexte anwenden.
Mit SE müssen E-Mails heruntergeladen, unter dem neuen SE-Algorithmus verschlüsselt und erneut hochgeladen werden. Dies wäre jedoch nur einmal pro Nachricht erforderlich und könnte geräteübergreifend verfügbar sein, ohne sich auf die Festplatte eines bestimmten Geräts zu verlassen. Von diesem Zeitpunkt an könnte der Server jedes Mal, wenn der Nutzer eine Suche auslöst, die vom spezifischen SE-Schema erlaubte Suchfunktion anwenden, und die Vertraulichkeit des Inhalts der Nachrichten bliebe unverändert. Wenn das zu gut klingt, um wahr zu sein, liegt das daran, dass es mit erheblichen Einschränkungen verbunden ist, die uns dazu veranlasst haben, einen traditionelleren Ansatz zu wählen. Das Gebiet der SE-Kryptografie ist hauptsächlich von akademischem Interesse, da die kryptografischen Verfahren in dieser Kategorie sehr restriktive Kompromisse haben.
- Diese Schemata sind so allgemein wie möglich gestaltet, um viele verschiedene Anwendungsfälle abzudecken. Das bedeutet, dass eine nicht-triviale Feinabstimmung der kryptografischen Primitive (zum Beispiel Sicherheitsparameter) erforderlich ist.
- Die Sicherheitsgarantien variieren von einem SE-Algorithmus zum anderen. Es ist sogar der Fall, dass manche Schemata die Leistung für zu viel Sicherheit opfern. Zum Beispiel ist es nicht unbedingt wichtig, dass der Server erfährt, ob eine E-Mail in der Datenbank eingefügt wurde, da er ohnehin weiß, dass eine neue E-Mail empfangen wurde!
- Umgekehrt hat die kryptografische Gemeinschaft keinen Konsens über die Sicherheitsgarantien von SE-Algorithmen erreicht, was dazu führt, dass immer noch neue und potenziell verheerende Angriffe gegen die bekanntesten Schemata veröffentlicht werden.
- Implementierungen sind selten und nicht bereit für den Einsatz in Produktionsumgebungen, da diese Schemata noch ziemlich akademisch sind. Jeder Versuch, eine solche Funktion zu entwickeln, hätte eine ad-hoc Implementierung fast aller ihrer Bausteine erfordert.
- Aufgrund des vorherigen Punktes ist die Leistung schlecht verstanden, und Tests wurden nur in begrenzten und kontrollierten Umgebungen durchgeführt, nie in freier Wildbahn.
Alles in allem ist dies wahrscheinlich das interessanteste Gebiet in der Suche nach Nachrichteninhalten, aber es erfüllte nicht unsere Anforderungen.
Unser Ansatz – Clientseitige Suche
Bei dem Problem, wie man den Inhalt von Nachrichten durchsucht, gibt es zwei Seiten zu berücksichtigen. Einerseits hat der Server alle E-Mails innerhalb eines Postfachs, aber sie sind mit einem Schlüssel verschlüsselt, den er nicht hat. Andererseits kann der Client jede Nachricht entschlüsseln, hat aber zu keinem Zeitpunkt Zugang zum gesamten Postfach. Offensichtlich sollte die Suche nach dem Inhalt von E-Mails, obwohl sie eine nützliche Funktion ist, das Sicherheitsmodell von Proton Mail nicht beeinträchtigen. Wie wir besprochen haben, ist dies mit einer serverseitigen Lösung angesichts der aktuellen Kryptografie schwierig zu erreichen. Deshalb haben wir uns für unsere erste Implementierung der Suche nach Nachrichteninhalten entschieden, dass der Client für das Durchsuchen der Nachrichten verantwortlich sein sollte.
Das ist bereits ein guter Ausgangspunkt, denn der Client erfüllt mehrere Kriterien, die für die Implementierung einer verschlüsselten Suchfunktion nützlich sind.
- In dem Moment, in dem der Nutzer sich einloggt, sind die kryptografischen Schlüssel, mit denen alle E-Mails verschlüsselt sind, lokal verfügbar und können jederzeit verwendet werden.
- Alle Nachrichten sind zugänglich; es geht nur darum, die entsprechenden Anfragen an den Server zu senden.
Obwohl es trivial erscheint, deuten diese beiden grundlegenden Tatsachen eines jeden Proton-Clients bereits auf eine mögliche Lösung für das Problem der Suche im Inhalt von E-Mails hin. Jedes Mal, wenn ein Nutzer eine Anfrage stellt, kann der Client:
- Die Nachricht vom Server abrufen
- Sie entschlüsseln
- Überprüfen, ob die E-Mail den Metadatensuchfiltern entspricht (zum Beispiel einem Zeitraum)
- Falls ja, suchen, ob das vom Nutzer eingegebene Schlüsselwort im Text oder in anderen Metadaten der E-Mail gefunden wird
- Falls ja, die E-Mail als Suchergebnis anzeigen
Es ist nicht schwer zu erkennen, dass dieser Ansatz schwerwiegende praktische Probleme hat. Zum einen gibt es viel Redundanz, weil Nachrichten für jede Anfrage abgerufen und entschlüsselt werden. Es ist nicht skalierbar: Nutzer mit kleinen Mailboxen finden es vielleicht akzeptabel, aber mit wachsender Nachrichtenanzahl steigt auch die Verlangsamung. Letztendlich müssten Server sehr viele Nachrichten gleichzeitig an alle Nutzer ausliefern, die ihre Posteingänge durchsuchen, wodurch die Gesamtbelastung sehr schnell prohibitiv wird.
Obwohl unpraktisch, bietet der oben genannte einfache Algorithmus und seine Nachteile einen interessanten Ansatz zur Verbesserung der Situation. Jede Suche müsste Nachrichten vom Server abrufen und entschlüsseln, aber diese Schritte sind völlig unabhängig von jeglichen Suchparametern. Mit anderen Worten, wir können sie als Vorverarbeitungsphase vor jeder Suche implementieren.
Wir nennen dies die Indexierungsphase, weil wir die Daten in einer lokalen Datenbank auf dem Client indexieren. Ist sie abgeschlossen, spiegelt der Index perfekt den Inhalt der gesamten Mailbox wider. Der Nutzer kann Suchen nach Nachrichteninhalten über die auf seinem Gerät gespeicherten Nachrichten durchführen, anstatt seine Nachrichten immer wieder abrufen zu müssen, was die Leistung und Skalierbarkeit drastisch verbessert. Die Logik des gesamten Verfahrens lässt sich dann wie folgt zusammenfassen.
- Bei Aktivierung der Suche nach Nachrichteninhalten, baue den lokalen Index auf. Die dafür benötigte Zeit variiert erheblich, je nachdem, wie viele Nachrichten die Mailbox enthält.
- Ist das erledigt, führe die Schritte 3, 4 und 5 des oben genannten Algorithmus aus, wann immer der Nutzer eine Suche auslöst.
Details zur lokalen Datenbank
Die Suchen selbst werden eigentlich nur durch die Punkte 3, 4 und 5 des oben genannten Algorithmus beschrieben. Abgesehen von einigen kleinen Details, macht unsere Implementierung genau das. Der Kern der Lösung – und das Forschungs- und Entwicklungsinteressanteste – war der lokale Index.
Zugrundeliegende Technologie
In unserem Web-Client verwenden wir die IndexedDB Web API(neues Fenster), um den lokalen Index zu erstellen. IndexedDB (IDB) ist ein transaktionales Datenbanksystem, basierend auf dem Schlüssel-Wert-Paradigma, in allen modernen Browsern. Es gibt mehrere praktische Gründe für diese Wahl, insbesondere im Vergleich zu anderen Arten von Web-Speicherlösungen(neues Fenster).
- IDB ist mit Blick auf JavaScript-Objekte konzipiert, was es flexibel und benutzerfreundlich für benutzerdefinierte Objekte macht.
- Es ist darauf ausgelegt, große Datenmengen mit seiner höheren Quote zu speichern. Das ist notwendig, um sehr große Mailboxen indexieren zu können.
- Das Abfragesystem ist flexibler. Zum Beispiel ist es möglich, den Bereich der Abfrage einzuschränken.
Aufbau der Datenbank
Der Indexierungsprozess beginnt, wenn ein Nutzer die Suche nach Nachrichteninhalten aktiviert. Wie erwähnt, ist es notwendig, den lokalen Index zu erstellen, und das ist eine Voraussetzung, bevor irgendeine Suche nach E-Mail-Inhalten stattfinden kann. Der Prozess ist ziemlich geradlinig, aber es lohnt sich, ihn zu durchlaufen, um einige Sicherheitsaspekte hervorzuheben. Für jede Nachricht werden die folgenden Schritte durchgeführt:
- Es wird vom Server abgerufen.
- Wir entschlüsseln die OpenPGP-Nachricht lokal mit dem entsprechenden privaten Schlüssel.
- Der Klartext der Nachricht wird von jeglichen HTML-Markierungen bereinigt, da diese für die Suchfunktion nicht relevant sind.
- Der endgültige Klartext wird zusammen mit allen Metadaten erneut verschlüsselt, diesmal mit einem symmetrischen Verschlüsselungsschlüssel unter Verwendung von WebCrypto.
- Der Chiffretext wird in IDB gespeichert.
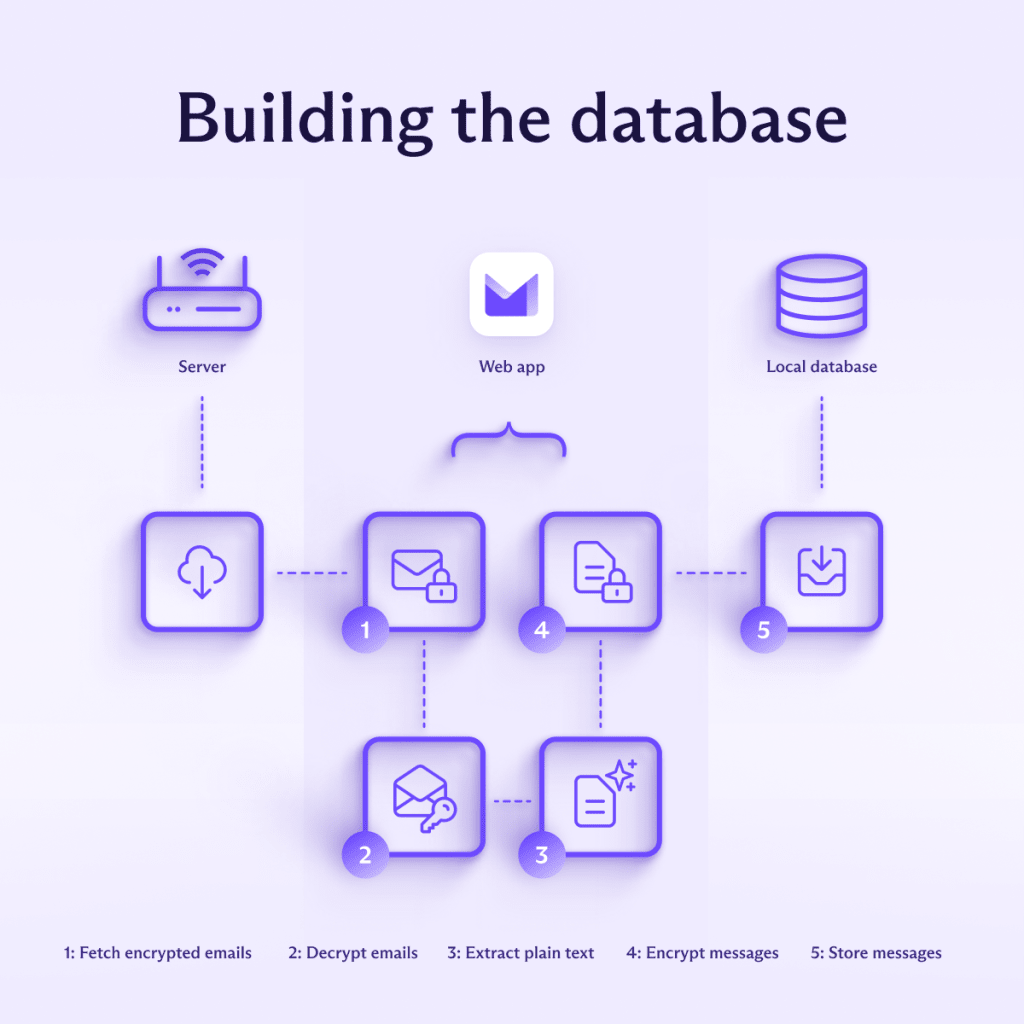
Der symmetrische Verschlüsselungsschlüssel wird zu Beginn der Indexierungsphase generiert und dient dazu, alle Nachrichten zu verschlüsseln, um deren Vertraulichkeit und Integrität zu gewährleisten – selbst im Falle eines kompromittierten Geräts. Wir verwenden AES-GCM dafür, da AES-GCM als Teil der Web Crypto API(neues Fenster) in allen modernen Browsern implementiert ist und schneller als OpenPGP ist. Der symmetrische Schlüssel selbst wird sicher lokal gespeichert, verschlüsselt unter dem Kontaktkey des Nutzers.
Da IDB eine einfache Schlüssel-Wert-Tabelle ist, in der der Wert (fast) jeder JavaScript-Wert sein kann, wird am Ende der Indexierungsphase jede Zeile durch Nachrichten-ID indiziert und enthält die Verschlüsselung der entsprechenden Nachricht. Beachte, dass trotz der angemessenen Geschwindigkeit der Web-APIs das Abrufen und Entschlüsseln von Nachrichten aus IDB einen Leistungsaufwand bedeutet. Um diesen Aufwand bei jeder Suche innerhalb derselben Sitzung zu vermeiden, wird der IDB (vollständig oder teilweise, abhängig von seiner Größe) im unverschlüsselten Zustand zwischengespeichert.
Vorwärtsindex vs. invertierter Index
Wir haben uns entschieden, die Struktur des Vorwärtsindex(neues Fenster) für unsere Nachrichteninhaltsuche zu verwenden. Das bedeutet, die Schlüssel sind die eindeutigen Identifikatoren der E-Mail und die Werte sind die Nachrichten selbst (abzüglich einiger HTML-Bereinigung, wie oben erwähnt).
Wenn wir von der eigentlichen Struktur der Datenbank abstrahieren, können wir sie als die untenstehende Tabelle darstellen. Der Wert jeder Zeile ist eine E-Mail (sowohl ihr Inhalt als auch Metadaten).
Es ist erwähnenswert, dass wir einen anderen beliebten Ansatz für diese Szenarien untersucht haben, nämlich den invertierten Index(neues Fenster). Die untenstehende Tabelle stellt ein abstraktes Beispiel dafür dar.
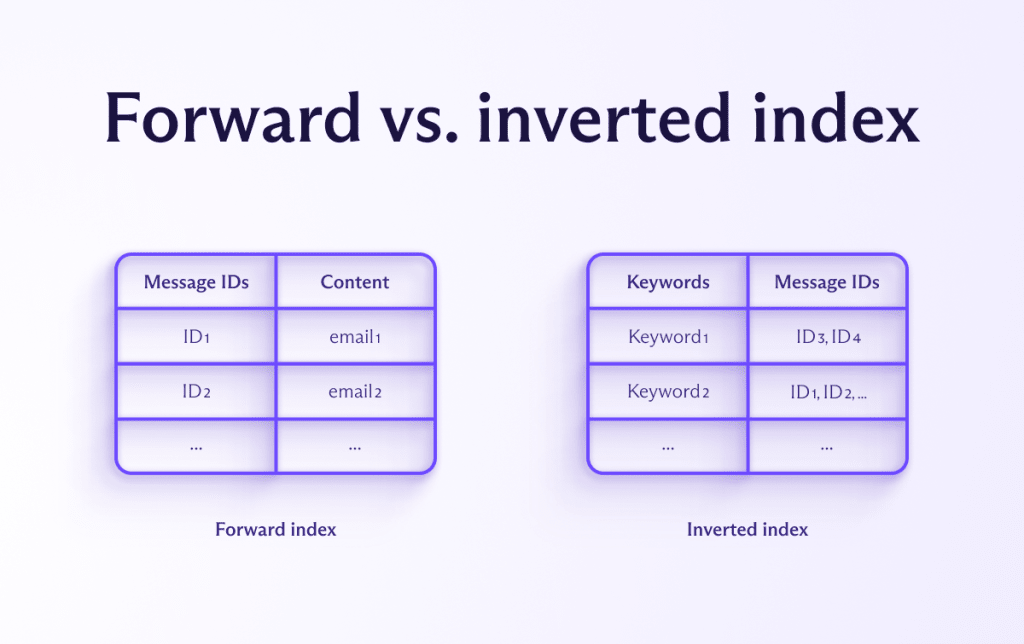
In diesem Fall sind Schlüsselwörter die Hauptkeys und der entsprechende Wert ist eine Liste von Nachrichten, die jedes Schlüsselwort enthalten. Dieser Ansatz ist in der Regel viel schneller als der Vorwärtsindex, da er nur die Datenbank nach den exakten (oder ähnlichen) Schlüsselwörtern, die der Nutzer abgefragt hat, durchsuchen muss, die Liste der Nachrichten abliest und sie anzeigt. Der Vorwärtsindex muss jede mögliche Nachricht durchsuchen, was auf sehr großen Skalen schnell unpraktisch wird.
Trotz dieses Unterschieds in der Leistung haben wir uns dennoch für einen Vorwärtsindex für diese erste Implementierung unserer Nachrichteninhaltsuche entschieden. Wir fanden heraus, dass Vorwärtsindizes mehrere Vorteile boten:
- Er ist konzeptionell einfacher und näher an der bereits verwendeten Nachrichtenschnittstelle des Webclients.
- Das Ausführen komplexerer Abfragen (zum Beispiel die Suche nach exakten Sätzen) ist einfacher, wenn man einen Vorwärtsindex verwendet, da wir Zugriff auf das gesamte Dokument haben. In einem invertierten Index hätten wir ohne zusätzliche Arbeit keine geordnete Liste von Schlüsselwörtern, was bedeutet, dass die Sätze auseinandergerissen werden.
- Die Größe des typischen Postfachs liegt gut im Rahmen dessen, was ein Vorwärtsindex schnell bewältigen kann, wodurch der Leistungsvorteil eines invertierten Index in den meisten Fällen marginal ist.
Wir werden jedoch weiterhin unsere Implementierung optimieren und alternative Ansätze untersuchen, einschließlich eines invertierten Index oder sogar einer durchsuchbaren Verschlüsselung, wenn es sich als machbar und notwendig für die Leistung erweist.
Fazit
Wenn wir das Sicherheitsmodell, das unsere Lösung erfüllen musste, noch einmal betrachten, sehen wir, dass die gewählte Lösung alle Tests besteht:
- Die Suche wird lokal auf dem Gerät des Nutzers durchgeführt, sodass die Anfrage nicht an einen Proton-Server weitergegeben wird.
- Alles, was benötigt wird, um die Ergebnisse anzuzeigen, wird lokal auf dem Gerät des Nutzers gespeichert (zum Beispiel Metadaten), sodass die Ergebnisse nicht an den Server weitergegeben werden. Ein Vorbehalt ist, dass beim Öffnen eines Suchergebnisses dieses erneut abgerufen werden muss, da die lokal gespeicherte Version nicht das benötigte HTML zum Rendern enthält. Der Server kann jedoch nicht ableiten, ob mehrere E-Mail-Öffnungen zur selben Anfrage (oder zu einer Suche) gehören, da beim Suchen keine Anfrage an den Server gesendet wird.
- Der private Schlüssel des Nutzers ist erforderlich, um die lokale Datenbank der Nachrichten zu entschlüsseln, sodass der Server keine Suche durchführen kann.
- Der Index wird lokal gespeichert und nie an den Server gesendet, daher kann der Server den Inhalt der E-Mails aus dem Index nicht lesen.
- Die Nachrichten und Metadaten werden verschlüsselt auf dem Gerät gespeichert, was sie vor Angreifern schützt, falls das Gerät kompromittiert wird. Das erfordert jedoch ein wenig Sorgfalt von dir: Das Abmelden von deinem Proton-Konto entfernt den Index nicht, verhindert aber, dass die App dich beim Öffnen des Browsers automatisch einloggt. Das Sichern des Geräts mit einem Passwort und einer vollständigen Festplattenverschlüsselung sind ebenfalls gute Praktiken und können Angreifer davon abhalten, den Inhalt der Festplatte deines Geräts zu lesen, falls sie es in die Hände bekommen.
Sicherheit und Privatsphäre gibt es nie umsonst. Manchmal scheint es so, als ob sie nichts kosten würden, weil der Preis minimal ist, wie eine kaum spürbare Leistungseinbuße beim Ausführen von Code. Andere Male erfordern sie eine komplette Neugestaltung von Funktionen und Funktionalitäten.
Unsere Erfahrungen mit der Suche nach Nachrichteninhalten zeigen, dass es trotz aller Schwierigkeiten möglich ist, umfassende Produkte zu entwickeln, die die Privatsphäre der Nutzer respektieren. Und die von uns entwickelte Suchfunktionalität kann schließlich auch von anderen Proton-Diensten genutzt werden, einschließlich Proton Drive(neues Fenster) und Proton Calendar(neues Fenster). Letztendlich glauben wir, dass der Aufwand, den wir in die Überarbeitung dieser Funktionen stecken, damit sie mit unserer Verschlüsselung funktionieren, ein kleiner Preis ist im Vergleich zu der Privatsphäre, die sie bewahren.






