
Cryptography is at the heart of all our services. This has enormous advantages because it provides all the necessary tools and constructions for us to develop features with built-in security and privacy. Occasionally, however, these protection layers can hinder basic functionalities that everybody has grown accustomed to from non-privacy-focused services. One example is the Proton community wanting to be able to search through their emails’ content on their Proton Mail app.
The dilemma is as easy to explain as it’s difficult to solve. At Proton, we store all messages in an encrypted state on our servers so that only the owner of the legitimate cryptographic key can access them. Since Proton servers do not have access to the keys, we cannot decrypt your emails, which means we cannot search their content. On the other hand, Proton’s web and mobile apps can access decrypted messages but typically lack the full view over the whole mailbox because they only fetch messages when the user interacts with them.
In other words, the problem can be stated as follows: How can we search emails’ content while retaining the usual security and privacy guarantees Proton has always offered?
Our security model for search
Before diving into any actual implementation details, it’s important to keep in mind the goals we set for the solution regarding the security and privacy it should guarantee. At Proton, the security model is the main driver of all design choices and technical decisions. The message content search could not fundamentally alter the privacy offering that Proton Mail(new window) provides. The following list provides a high-level overview of some privacy concerns related to searching message content and how we addressed them.
- When searching, we shouldn’t leak the query.
- When searching, we shouldn’t leak the set of results.
- The server shouldn’t be able to perform a search.
- The server shouldn’t be able to learn the contents of emails.
- If the local device is compromised after it’s shut down, an attacker shouldn’t be able to learn the contents or metadata of emails.
These are the criteria that we always kept in mind as we evaluated our possible solutions.
Searchable encryption – A theoretically optimal solution
The field of cryptography is full of constructions that go way beyond achieving the most basic security notions (i.e., authenticity, confidentiality, and integrity of data) and offer advanced functionalities to operate on the data without sacrificing too much on the privacy front. In other words, several algorithms have been built to allow the application of functions over ciphertexts, making them capable of preserving confidentiality while performing computations. These cryptographic schemes are called searchable encryption (SE) algorithms when they apply a search function to ciphertexts.
Using SE, emails need to be downloaded, encrypted under the new SE algorithm, and re-uploaded. However, this would be required only once per message and could be available across devices without relying on the disk of a specific device. From that point on, the server could apply the searching function allowed by the specific SE scheme every time the user triggers a search, and the confidentiality of the messages’ content would remain unaltered. If this seems too good to be true, it’s because it comes with severe limitations, which led us to choose a more traditional approach. The field of SE cryptography is mostly limited to academic interest because cryptographic schemes in this category have such restrictive trade-offs.
- These schemes are designed to be as general as possible to fit many different use cases. This means that some non-trivial fine-tuning of the cryptographic primitive (for example, security parameters) is required.
- The security guarantees vary from one SE algorithm to another. It’s even the case that some schemes sacrifice performance for too much security. For example, we don’t necessarily care that the server learns whether an email has been inserted in the database as it already knows a new email has been received!
- Conversely, the cryptographic community hasn’t reached a consensus on the security guarantees of SE algorithms, leading to new and potentially devastating attacks still being published against the most well-known schemes.
- Implementations are rare and not ready for production environments since these schemes are still fairly academic. Any attempt at developing such a feature would have required an ad-hoc implementation of almost all its building blocks.
- Due to the previous point, performance is poorly understood, and tests have only been carried out in limited and controlled environments, never in the wild.
All in all, this is probably the most interesting field in message content search, but it didn’t meet our requirements.
Our approach – Client-side searching
When facing the problem of how to search message content, there are two sides at play. On the one hand, the server has all the emails inside a mailbox, but they’re encrypted by a key it doesn’t have. On the other hand, the client can decrypt any message but doesn’t have access to the full mailbox at any point in time. Clearly, searching the content of emails, despite being a useful functionality, shouldn’t break the security model Proton Mail already provides. As we discussed, this is difficult to achieve with a server-side solution given current cryptography. Thus for our first implementation of message content search, we decided that the client should be responsible for searching messages.
This is a good starting point already, as the client checks several boxes that are useful for implementing an encrypted search feature.
- The moment the user logs in, the cryptographic keys by which all emails are encrypted are locally available and can be used at any time.
- All messages are accessible; it’s just a matter of sending the appropriate requests to the server.
Despite looking trivial, these two basic facts of any Proton client already point toward a potential solution to the problem of searching emails’ content. Every time a user performs a query, the client can:
- Fetch the message from the server
- Decrypt it
- Check whether the email matches the metadata search filters (for example, a date range)
- If it does, search whether the keyword entered by the user is found in the body or in any other metadata of the email
- If it does, show the email as a search result
It isn’t hard to see that this approach has severe practical problems. For one, it has a lot of redundancy because messages are fetched and decrypted for every query. It doesn’t scale: users with small mailboxes might find it acceptable, but as the number of messages grows, so does the slowdown. Finally, servers would need to serve a lot of messages to all the users that search their inboxes at the same time, making the total workload prohibitive very quickly.
Despite being impractical, the above simple algorithm and its drawbacks offer an interesting lead to improve the situation. Any search would need to fetch messages from the server and decrypt them, but these steps are completely independent of any search parameter. In other words, we can implement them as a pre-processing phase before any search.
We call this the indexing phase because we index the data in a local database on the client. Once it’s completed, the index perfectly mirrors the content of the whole mailbox. The user can perform message content searches over the messages stored on their device rather than having to fetch their messages over and over, drastically improving performance and scalability. The logic of the overall procedure can then be summarized as follows.
- Upon activation of message content search, build the local index. The amount of time this takes varies considerably depending on how many messages the mailbox contains.
- Once that’s done, execute steps 3, 4, and 5 of the above algorithm whenever the user triggers a search.
Details on the local database
Searches themselves are really just described by points 3, 4, and 5 of the algorithm above. Apart from some minor details, that’s pretty much what our implementation does. The core of the solution – and the most interesting to research and develop – was the local index.
Underlying technology
On our web client, we use the IndexedDB Web API(new window) to build the local index. IndexedDB (IDB) is a transactional database system based on the key-value paradigm in all modern browsers. There are several practical reasons behind this choice, especially in relation to other types of web storage(new window) solutions.
- IDB is designed with JavaScript objects in mind, making it flexible and friendly to custom objects.
- It’s intended to store large amounts of data using its higher quota. This is necessary to be able to index very large mailboxes.
- The query system is more flexible. For example, it’s possible to restrict the range of the query.
Building the database
The indexing process starts when a user activates message content search. As mentioned, it’s necessary to build the local index and is a pre-condition before any search of emails’ content can happen. The process is fairly straightforward, but it’s worthwhile to go through it to highlight some security aspects. For each message, the following steps are carried out:
- It’s fetched from the server.
- We locally decrypt the OpenPGP message using the appropriate private key.
- The plaintext of the message is cleaned of any HTML markups, as those aren’t relevant to the search functionality.
- The final plaintext, along with all its metadata, is encrypted again, this time by a symmetric encryption key, using WebCrypto.
- The ciphertext is stored in IDB.
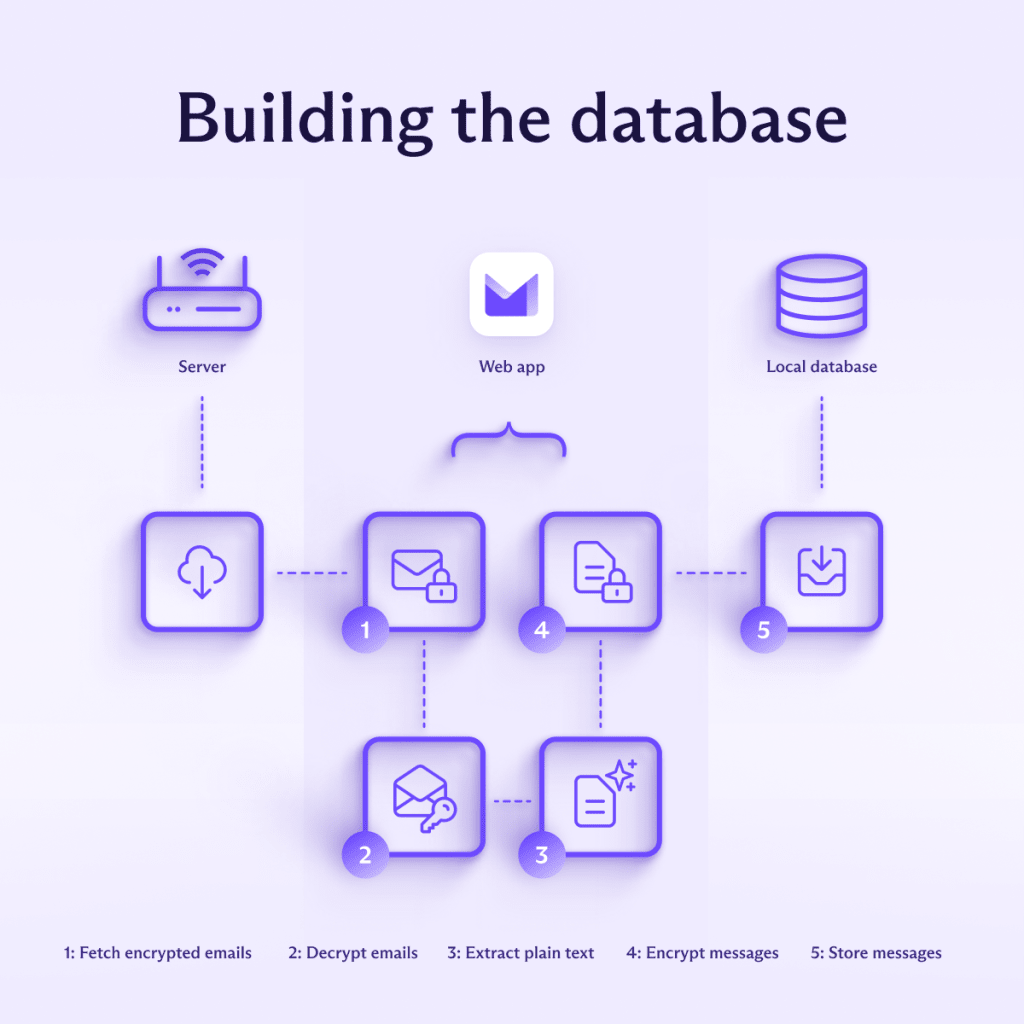
The symmetric encryption key is generated at the beginning of the indexing phase and is used to encrypt all messages to ensure their confidentiality and integrity – even in the case of a compromised device. We use AES-GCM for this, since AES-GCM is implemented in all modern browsers as part of the Web Crypto API(new window), which is faster than OpenPGP. The symmetric key itself is safely stored locally, encrypted under the user’s contact key.
Since IDB is a simple key-value table where the value can be (almost) any JavaScript value, at the end of the indexing phase, every row is indexed by message ID and contains the encryption of the corresponding message. Note that despite Web APIs being reasonably fast, fetching and decrypting messages from IDB does have a performance cost. To avoid paying this cost for every search within the same session, the IDB is (fully or partially, depending on its size) cached in unencrypted form.
Forward index vs. inverted index
We chose to use the forward index(new window) structure for our message content search. This means the keys are the email’s unique identifiers, and the values are the messages themselves (minus some HTML cleanup, as stated above).
If we abstract away from the actual structure of the database, we can represent it as the table below. The value of each row is an email (both its body and metadata).
It’s worth mentioning that we explored another popular approach to deal with these scenarios, namely the inverted index(new window). The table below represents an abstract example of it.
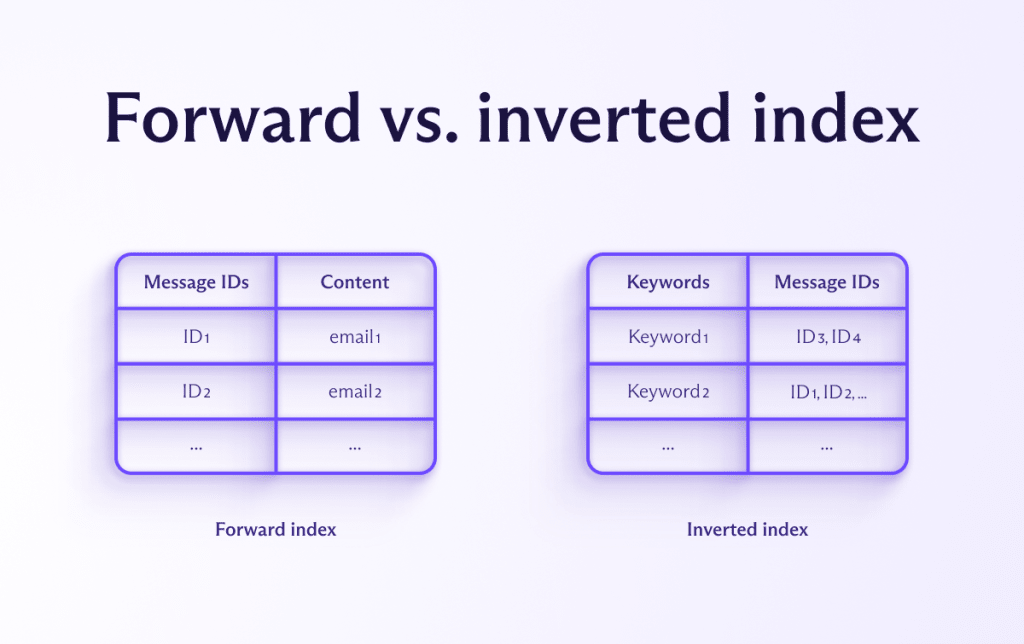
In this case, keywords are the main keys, and the corresponding value is a list of messages containing each keyword. This approach is usually much faster than the forward index because it only has to search the database for the exact(ish) keywords the user queried, read off the list of messages, and display them. The forward index must search every possible message, which quickly becomes impractical on very large scales.
Despite this difference in performance, we still chose to use a forward index for this first implementation of our message content search. We found that forward indices offered several advantages:
- It’s conceptually simpler and closer to the web client’s message interface that’s already in use.
- Running more complex queries (for example, searching for exact sentences) is easier when using a forward index because we have access to the full document. In an inverted index, we wouldn’t have an ordered list of keywords without doing additional work, which means the sentences are broken apart.
- The size of the typical mailbox is well within what a forward index can quickly handle, making the performance advantage of an inverted index marginal in most cases.
However, we’ll continue to optimize our implementation and investigate alternative approaches, including an inverted index or even searchable encryption, if it proves viable and necessary for performance.
Conclusions
If we revisit the security model that we said our solution had to meet, we see that the solution we chose passes all the tests:
- The search is performed locally on user’s device, so the query isn’t leaked to a Proton server.
- Everything that’s needed to show the results is stored locally on the user’s device (for example, metadata), so the results aren’t leaked to the server. A caveat is that upon opening a search result, it has to be fetched again as the locally stored version doesn’t have the HTML needed to render. However, the server can’t infer whether multiple email openings belong to the same query (or to a search) since no query is sent to the server when searching.
- The user’s private key is required to decrypt the local database of messages, so the server can’t perform a search.
- The index is stored locally and never sent to the server, so the server can’t read the contents of emails from the index.
- The messages and metadata are stored encrypted on the device, which helps protect them from attackers if the device is compromised. This will still require some care from the user: logging out of your Proton account doesn’t remove the index but does prevent the app from automatically logging you in upon opening the browser. Securing the device with a password and full-disk encryption are also good practices and can stop attackers from reading the contents of of your device’s disk if they manage to steal it.
Security and privacy never come for free. Sometimes it might seem like they do because the price is minimal, like a barely noticeable performance penalty when executing some code. Other times, they require a complete re-design of features and functionalities.
Our journey with message content search shows that, despite all the difficulties, building rich products that respect users’ privacy is possible. And the search functionality we developed can eventually be used by other Proton services, including Proton Drive(new window) and Proton Calendar(new window). Ultimately, we believe the effort we put into reworking these functionalities so that they can work with our encryption is a small price to pay when compared to the privacy they preserve.





