






The first month of 2023 has brought brutal layoffs from Big Tech(new window), a potential ban of TikTok in the US(new window), and another Twitter breach. But the biggest development of this new year has to be the ascent of ChatGPT(new window).
Read about the biggest AI development of 2025: DeepSeek
The chatbot can produce remarkably human-sounding text and, depending on the prompt, even generate creative responses that sound like they could not possibly have come from a computer:
The pace of progress is staggering. And, if past technology is any model, it will only accelerate. The current generation of chatbots has already shattered the Turing test, making it very likely that AI-powered chatbots will soon be applied to all kinds of jobs, tasks, and devices in the near future. It’s only a matter of time before interacting with AI is a regular part of our daily routine. This proliferation will only further accelerate AI’s development.
This is all good news! AI is a powerful tool that could lead to all sorts of new developments and breakthroughs. However, as with any tool, we must make sure it’s used and developed responsibly. At Proton, we’ve noticed that for all the publicity around ChatGPT, there’s been little examination of the privacy questions that AI raises.
We’re going to explain how AI, like ChatGPT, needs data to develop and how AI in the future could present new challenges to our privacy.
We even interviewed ChatGPT about the future of privacy, and it came up with some good answers.
You can see more of our conversation with ChatGPT(new window) over the next few days.
Training AI requires data – lots of data
Massive amounts of data are required to train and improve most AI models. The more data that’s fed into the AI, the better it can detect patterns, anticipate what will come next, and create something entirely new. The process looks something like this:
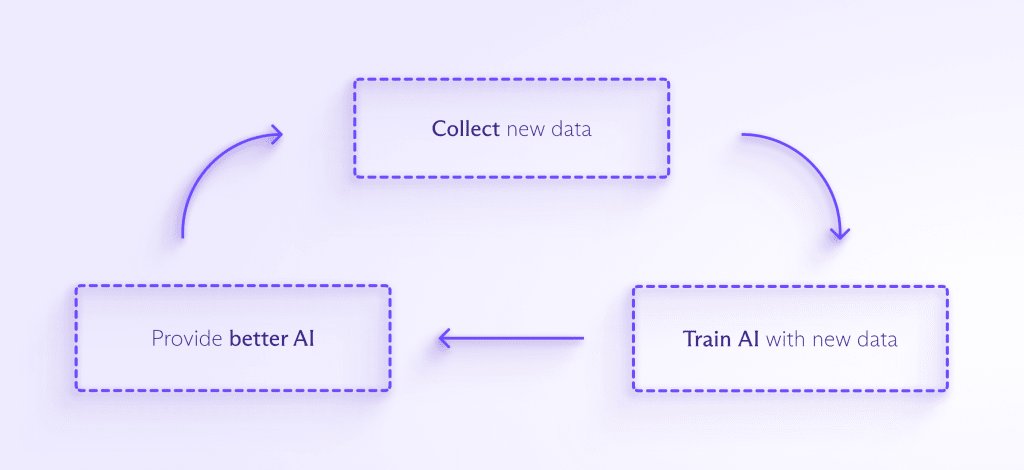
As AI is integrated into more consumer-facing products, there will be pressure to collect even more data to train it. And as people interact with AI more and more often, companies will likely want to collect your personal data to help your AI assistant understand how it should respond to you, specifically.
This leads to all kinds of problems. An AI trained on data will only learn how to deal with situations raised by the dataset it has seen. If your data isn’t representative, the AI will replicate that bias in its decision making, which is exactly what Amazon saw when its AI recruitment bot penalized women candidates(new window) after being trained on resumes in a male-dominated dataset.
Similarly, if AI encounters a situation it never saw in its training data, it might not know what to do. This was the case with a self-driving Uber vehicle that killed a pedestrian(new window) that it failed to identify since the person was outside of a crosswalk.
And before an AI can be trained on data, that data must be cleaned, which means properly formatting it and deleting racist, sexist, violent, or objectionable content. Much like content moderation for companies like Meta, this task is typically grueling, poorly paid, and hidden from the public. It recently came to light that OpenAI relied upon hundreds of people in Kenya(new window) to clean the data for GPT-3 who ended up being traumatized by the work.
For AI to avoid these types of biases and blindspots, companies will need to collect even more data than Big Tech currently does to sell personalized ads. You might not know it, but these efforts have already begun.
As an example of the scale we’re talking about, the entirety of English Wikipedia, which comprises some 6 million articles, made up only 0.6% of the training data for GPT-3(new window), of which ChatGPT is a variant.
A more notorious example is Clearview AI(new window), which scraped people’s images off the web and used them to train its facial surveillance AI without people’s permission. Its database contains roughly 20 billion images.
Clearview has received all kinds of lawsuits, fines, and cease-and-desist orders over its blatant disregard for people’s privacy. However, it has been able to avoid paying many fines and has resisted deleting data despite regulators’ orders(new window), potentially paving a path that other unscrupulous AI developers could follow.
Another concern is that the ubiquity of AI could make such data collection nearly impossible to avoid.
The AI will hear your case now
We are currently concerned about the amount of data that Big Tech collects from us while we browse online or via internet-connected smart devices. However, the number of smart devices and the amount of overall data collection will skyrocket as AI and chatbots improve. And AI will begin taking over portions of our life that are already dominated by algorithms, making it impossible to escape.
Currently, depending on where you live, an algorithm could decide whether you receive bail(new window) before your trial, whether you qualify for a home loan(new window), and how much you pay for health insurance(new window). AI will take over these essential tasks and likely expand into even more sectors. There seems to be a never-ending quest to use AI to predict crime(new window). And experiments have already been run using GPT-3 as a medical chatbot(new window) (with some disastrous results).
As AI is applied to new functions, it will be exposed to more and more sensitive information, and it will become more and more difficult for people to avoid sharing their information with AI. Also, once data is collected, it’s very easy for it to be repurposed or used for something people never consented to.
We don’t know what AI will look like in the future
In 1965, computers took up entire rooms(new window). That was the same year Gordon Moore came up with what came to be called Moore’s Law(new window), which states that the number of transistors that can be fit onto an integrated circuit will double every two years. His prediction proved remarkably accurate for over 40 years and only recently broke down. But even he could not have predicted how advanced our current computers are.
We will very likely look back at ChatGPT in the same way we look at a computer from the ‘60s and marvel at how anyone was able to get anything done with it. The simple fact is we’re at the beginning of a momentous technological journey, and we have no idea where it will take us.
Currently, people are concerned about how Big Tech platforms can subtly influence our decision making and create impossible-to-escape filter bubbles. However, these could seem like blunt instruments compared to an AI-powered search engine or new service. Additionally, AI could get so good at pattern recognition that it develops the ability to de-anonymize data or match identities across disparate datasets. This all sounds speculative, but that’s simply because we have no idea what the upper limits of AI capability are.
What can we do to preserve privacy in an AI-powered future?
The good news is that there are things we can do right now to ensure that AI is trained responsibly using anonymized data. We plan on writing another article in the future on the methods companies can use to train AI on datasets while still protecting people’s privacy.
If you’re concerned about your privacy, it’s never too soon to begin protecting your information. If you encrypt your data (with services like Proton Mail or Proton Drive), you will remove it from Big Tech or public databases, preventing it from being used to track you or train AI.
You can also use sites like Have I Been Trained(new window) to see if any of your images have already been used to train AI. Unfortunately, even if you discover that one of your images was used without your permission, it’s not always easy to figure out how to get it removed(new window).
As for policymakers, they can begin shaping frameworks for AI use that enshrine the right to privacy. But we need to act now. AI will likely develop at an exponential rate, meaning we need to answer these questions now before it’s too late.
The first thing that can be done is that every country can pass a data privacy law that limits what types of personal data can be collected and what that data can legally be used for. This would make it easier to crack down on companies like Clearview AI.
Looking forward, policymakers can require that AI companies provide transparency into how their algorithms and AI models work, or at least into the datasets they’re using to train their systems. This will also help these companies avoid perpetuating the biases and blindspots in AI that we discussed earlier.
Policymakers should also force AI companies to submit their models to regular audits and have independent data privacy officers to make sure data is being used responsibly.
This is an exciting moment in human history. AI is an unexplored frontier, but before we venture forth, we need to make sure we’ve secured our basic human rights.
Update January 30, 2023: We removed a reference about the workers who cleaned data for ChatGPT being poorly paid after the payment figures were released.




