
Le 3 novembre, LinkedIn commencera à partager vos données avec Microsoft et ses affiliés pour l’entraînement de l’IA. Vous êtes inscrit par défaut, mais il est encore temps de faire quelque chose à ce sujet.
Cette nouvelle politique d’IA de LinkedIn semble s’inscrire dans la stratégie plus large de Microsoft(nouvelle fenêtre) consistant à alimenter son écosystème d’IA avec plus de données. Quelques semaines plus tôt, l’entreprise a annoncé que les documents Word commenceraient à s’enregistrer sur OneDrive par défaut, Excel et PowerPoint devant bientôt suivre. Cette décision a suscité des inquiétudes quant à la manière dont le déplacement de fichiers personnels ou professionnels dans le cloud de Microsoft pourrait croiser l’entraînement de l’IA, surtout si l’on considère l’investissement de plusieurs milliards de dollars de Microsoft dans OpenAI, le créateur de ChatGPT.
- Pourquoi LinkedIn modifie-t-il ses paramètres de confidentialité des données ?
- Quelles données LinkedIn utilisera-t-il pour l’entraînement de l’IA ?
- Comment se désinscrire de l’entraînement de l’IA sur LinkedIn
- Vos données de carrière ne devraient pas servir de carburant à l’entraînement de l’IA
Pourquoi LinkedIn modifie-t-il ses paramètres de confidentialité des données ?
Le 18 septembre, LinkedIn a annoncé(nouvelle fenêtre) qu’à partir du 3 novembre 2025, les données des utilisateurs de l’UE, de l’EEE et de la Suisse seront partagées avec Microsoft et ses affiliés pour l’entraînement de l’IA. Vous pouvez toujours vous désinscrire après cette date, mais cela n’affectera pas les données passées : les informations que vous avez partagées sur LinkedIn jusqu’à ce point sont en libre accès.
Cette annonce intervient après qu’un procès en Californie a accusé LinkedIn(nouvelle fenêtre) de partager secrètement des messages privés avec des tiers pour entraîner des modèles d’IA. L’entreprise a nié les allégations et a mis à jour sa documentation de confidentialité peu après, précisant que les utilisateurs du Royaume-Uni, de l’EEE et de la Suisse étaient exclus de ces changements. Mais maintenant, la plateforme étend les mêmes politiques d’entraînement de l’IA à ces régions mêmes.
Quelles données LinkedIn utilisera-t-il pour l’entraînement de l’IA ?
Voici quel type de données LinkedIn peut être utilisé pour les pipelines d’IA :
- Données de profil, y compris le nom, la photo, le poste actuel, l’expérience professionnelle passée, l’éducation, l’emplacement, les compétences, les publications, les brevets, les recommandations et les approbations.
- Données liées à l’emploi, telles que les CV, les réponses aux questions de présélection et les détails de candidature.
- Contenu des membres, tel que les publications, les articles, les réponses aux sondages, les contributions et les commentaires.
- Données de groupes, y compris l’activité et les messages.
- Commentaires, y compris les notes et les réponses que vous fournissez. Après votre désinscription, LinkedIn peut toujours utiliser vos commentaires et les associer à vous.
Le contenu suivant est explicitement exclu : les messages privés, les identifiants de connexion, les moyens de paiement, les informations de carte de paiement et les données de salaire ou de candidature fournies par les membres qui peuvent être liées à un individu spécifique.
Si LinkedIn a des raisons de croire que vous avez moins de 18 ans — par exemple, si vous êtes à l’école secondaire ou son équivalent local — vos données ne seront pas utilisées pour entraîner des modèles d’IA générant du contenu, même si votre paramètre est activé.
LinkedIn précise que toutes ces informations peuvent être utilisées par ses modèles d’IA générative — des systèmes qui génèrent du contenu tel que des publications suggérées ou des messages rédigés automatiquement. Bien qu’il fournisse un paramètre de désinscription, il ne s’applique qu’à l’IA générant du contenu. Pour empêcher LinkedIn d’utiliser vos commentaires pour des modèles d’IA non liés au contenu — comme la personnalisation, la sécurité, la confiance ou l’anti-abus — la seule option est de soumettre un formulaire d’objection au traitement des données.
Comment se désinscrire de l’entraînement de l’IA sur LinkedIn
Voici comment vous pouvez vous désinscrire de l’entraînement de l’IA dans vos paramètres de confidentialité :
- Sélectionnez Paramètres et confidentialité.
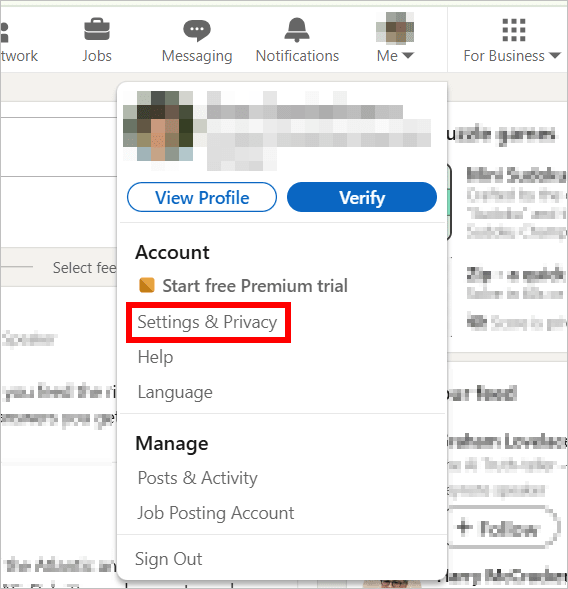
- Allez dans Confidentialité des données → Données pour l’amélioration de l’IA générative.
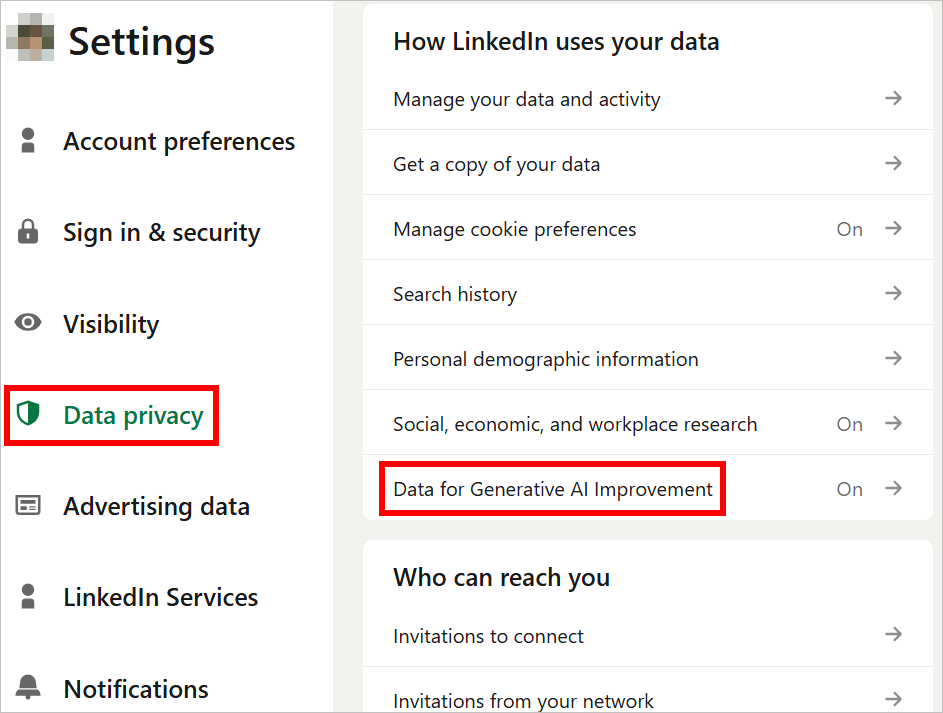
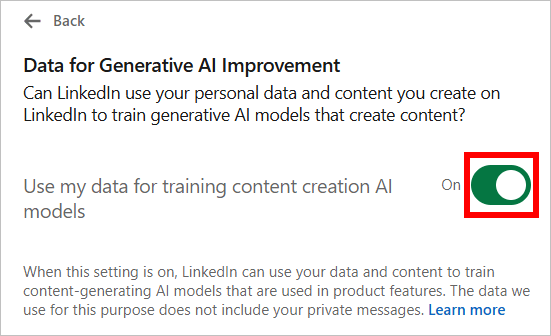
- Désactivez Utiliser mes données pour entraîner des modèles d’IA de création de contenu.
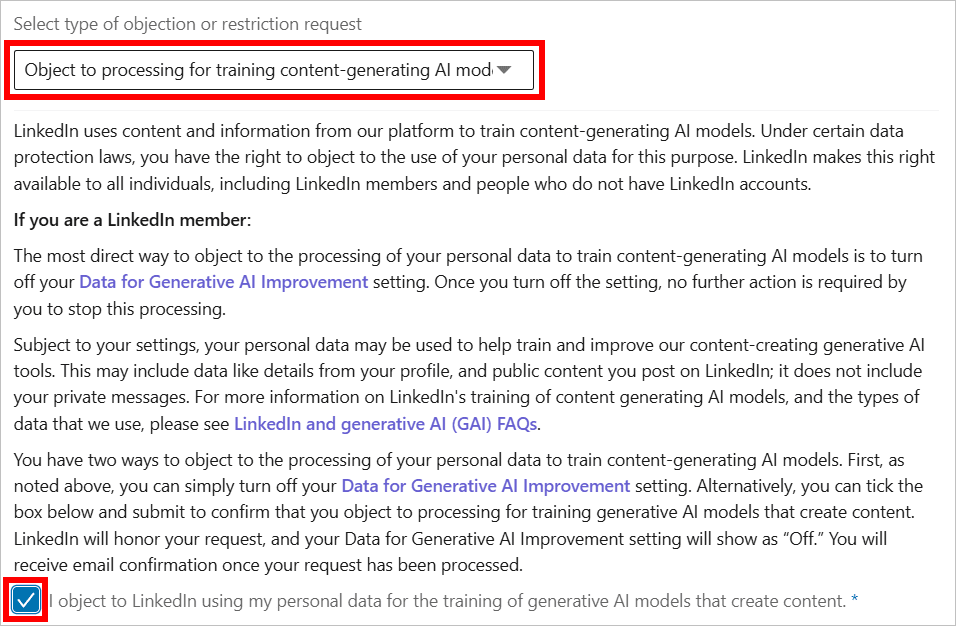
- Accédez au Formulaire d’objection au traitement des données(nouvelle fenêtre), sélectionnez S’opposer au traitement pour l’entraînement de modèles d’IA générant du contenu, et envoyez une demande. Les non-membres peuvent également déposer une objection si leurs données personnelles ont été partagées sur LinkedIn par un membre.
Si vous êtes aux États-Unis ou dans une autre région où LinkedIn a déjà déployé ces paramètres, vous êtes probablement déjà affecté. Et après le 3 novembre, les utilisateurs de l’UE, de l’EEE et de la Suisse seront également inclus. Mais vous pouvez toujours prendre des mesures pour réduire votre exposition :
- Examinez et nettoyez les anciennes publications qui peuvent inclure des informations sensibles. Par exemple, vous pouvez aller dans Gérer → Publications et activité pour voir facilement tout ce que vous avez publié.
- Examinez votre profil de compte et supprimez tout ce que vous n’êtes pas à l’aise de partager avec les modèles d’IA de LinkedIn, comme la date de naissance, le numéro de téléphone ou l’adresse.
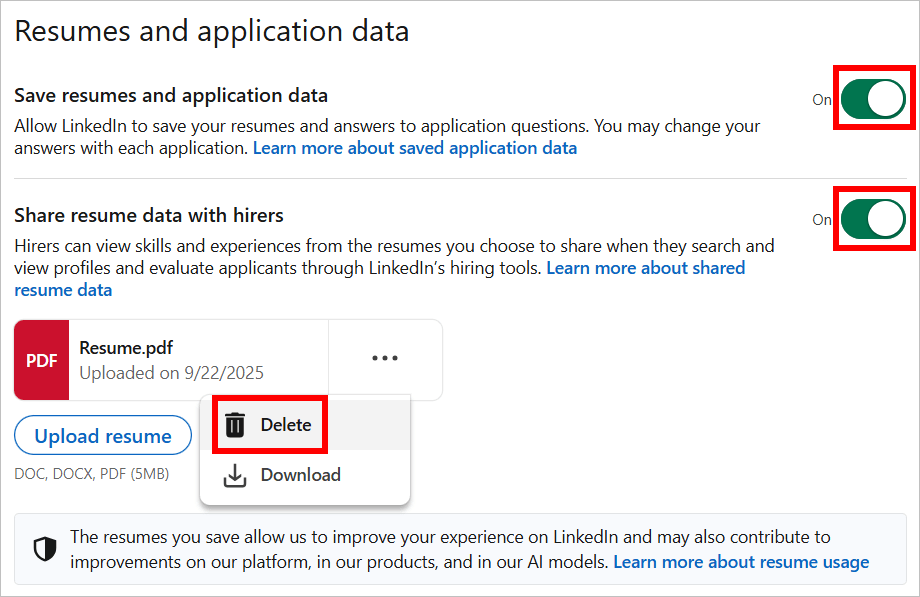
- Allez dans Confidentialité des données → Paramètres de candidature et supprimez tous les CV que vous avez importés sur LinkedIn.
- Partez du principe que tout contenu public que vous publiez, tel que les compétences, les commentaires ou les informations sur le secteur, peut être utilisé pour entraîner l’IA.
Note : Vos informations peuvent toujours se retrouver dans l’entraînement de l’IA si quelqu’un d’autre les partage. Par exemple, si un collègue republie votre article ou référence votre CV, ces informations peuvent toujours être aspirées dans le pipeline d’entraînement.
Vos données de carrière ne devraient pas être du carburant pour l’entraînement de l’IA
LinkedIn n’est pas la première plateforme à étendre ses ensembles de données d’entraînement d’IA en inscrivant les utilisateurs par défaut. Facebook, par exemple, a (nouvelle fenêtre)utilisé des publications publiques(nouvelle fenêtre), et Google a récemment conclu un accord avec Reddit(nouvelle fenêtre). Mais en tant que plateforme de recrutement qui stocke des CV, des candidatures et des interactions professionnelles, l’initiative de LinkedIn soulève des inquiétudes sur la façon dont votre identité de carrière numérique alimente les pipelines d’IA.
Chez Proton, nous croyons que votre historique professionnel et vos données de carrière devraient rester les vôtres. C’est pourquoi nous construisons des outils avec le chiffrement de bout en bout, afin que nous ne puissions pas accéder à vos informations privées, quoi qu’il arrive. Et nous ne les utilisons jamais pour entraîner des modèles d’IA. Notre métier est de protéger vos données, pas de les réutiliser.






