
今の子どもたちは、初めてオンラインになるその瞬間からデータを収集・保持するよう設計されたシステムの中で育っています。学校用アカウントや初めてのメールアドレス、あるいはメッセージングアプリとして始まったものが、その行動や交友関係、ユーザー情報を長期にわたって記録するものになり得ます。そして、そのデータは何年にもわたってアクセス可能な状態のまま残る可能性があります。
Proton の新たな調査は、そのシステムが大規模に及ぼす結果を示しています。過去10年間で、Google、Apple、Meta は350万件を超えるユーザーアカウントのデータを米当局と共有しており、企業がこうした要請の報告を始めて以来770%の増加です。外国情報監視法(FISA)に基づく開示を含めると、その総数は690万件に膨らみます。
オンライン上の子ども時代の設計を Big Tech に委ねる本当の危険は、まさにここにあります。広告のターゲティング、AI の学習、プロファイル構築といった商業目的で集められたデータは、後に国家監視にさらされる可能性があります。この仕組みがさらに深まれば、次世代は、プライバシーが徐々に弱められるのではなく、最初から組み込まれていないインターネットを受け継ぐことになります。
- 調査が示す Big Tech と政府の提携の実態
- これが可能なのは、Big Tech がお客様のデータを読める状態のまま保持しているからです
- 親たちは、この仕組みがすでに子どもたちを守れていないことを知っています
- 最初から子どものリスクを減らす方法
- 次の世代がこの欠陥のある仕組みを受け継ぐ必要はありません
調査が示す Big Tech と政府の提携の実態
当社の2025年の分析では、Big Tech が保有するユーザーデータへの政府のアクセスが、それまでの10年間で急増していたことがわかりました。最新の透明性レポートは、その傾向が続いていることを示しています。
米当局は今もユーザーデータの入手を Big Tech に依存しています
2014年末から2025年初頭にかけて、Google、Meta、Apple は通常の要請に応じて、350万件を超えるユーザーアカウントのデータを米当局と共有しました。
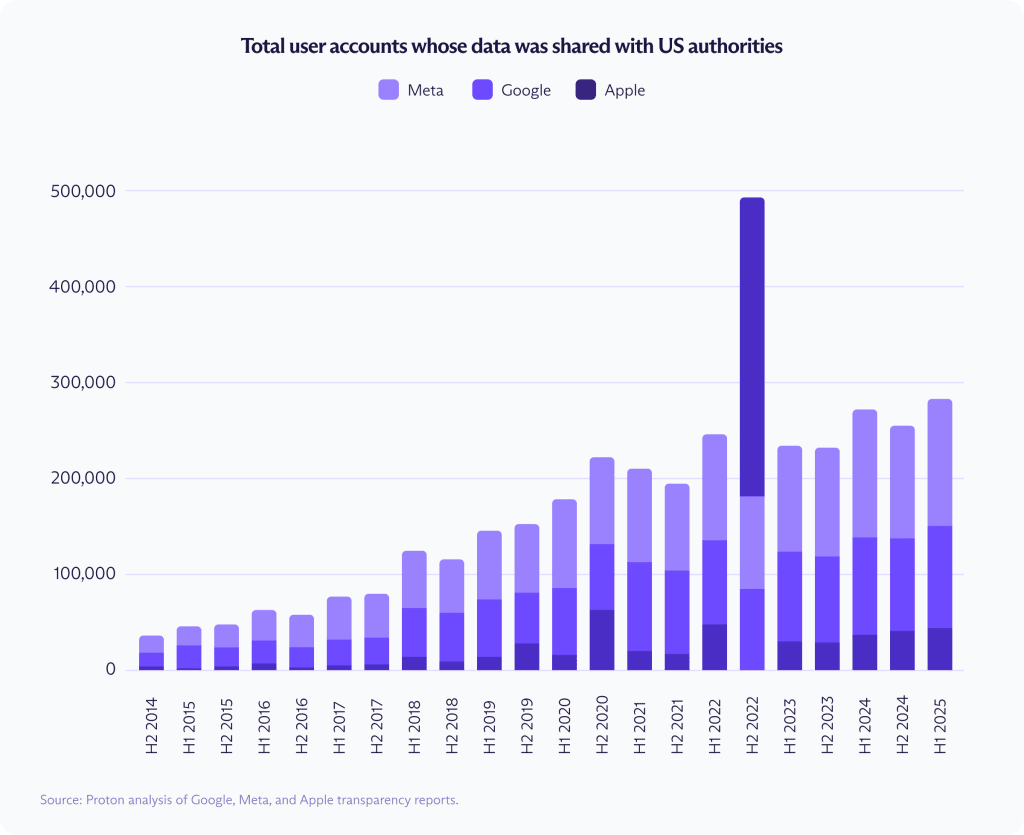
この期間に、開示されたアカウント数は Google で557%、Meta で668%、Apple で927%増加しました。2025年上半期だけでも、これらの企業は28万2,000件を超える米国アカウントのデータを開示しました。

350万件という数字は、標準的な透明性開示で報告される通常の政府要請を反映したものです。これには、国家安全保障上の規則に基づいて別枠で、より少ない詳細しか示されずに報告される外国情報監視法(FISA)に基づく要請は含まれていません。FISA に基づくコンテンツ要請を含めると、2024年末までのアカウント開示総数はおよそ670万件に達します。

2014年から2024年にかけて、報告された FISA コンテンツ要請は Meta で2,486%、Google で649%増加しました。Apple は2014年までさかのぼる比較可能なデータを公開していませんが、同社の開示された FISA コンテンツ要請は2018年から2024年の間に443%増加しました。区切りを2024年としているのは、通常の透明性データとは異なり、FISA の報告がまだ2025年まで及んでいないためです。
EU の要請は急増しています
総件数では欧州各国政府は米国に及びませんが、欧州連合全体での要請は引き続き急速に増えています。
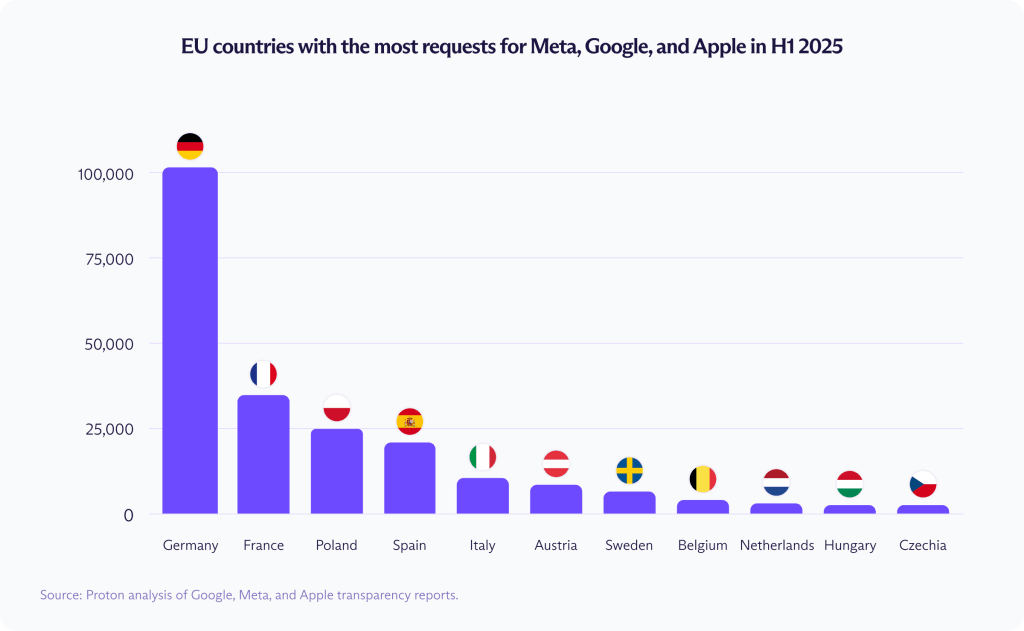
2025年上半期、EU加盟国は231,199件のユーザーアカウントに関するデータを要請しており、前年同期の164,472件からおよそ40%増加しました。2014年末以降、総要請件数は1,100%超増えています。
増加は均等に分布しているわけではありません。2025年上半期に最も大きな割合を占めたのはドイツで、101,811件のユーザーアカウントに関するデータを要請しました。次いでフランス(36,831件)、ポーランド(24,373件)、スペイン(20,984件)となっています。
これが可能なのは、Big Tech がお客様のデータを読める状態のまま保持しているからです
問題なのは、企業が合法的な政府要請に従うことではありません。どの企業も、その国で事業を続ける以上、有効な法的命令には応じなければならないからです。より根深い問題は、Google、Meta、Apple が、自社で依然としてアクセスできる形の膨大な個人データを収集・保持することを前提にシステムを構築してきた点です。企業が鍵を持っていれば、お客様のデータを読むことができます。読めるのであれば、提出を強制される可能性があります。
エンドツーエンド暗号化は、開示され得る内容を制限する最も確実な方法です。企業は復号化できないものを引き渡せないからです。多くても、実質的に読むことのできない暗号化済みのデータを差し出すことしかできません。しかし Big Tech は、その種の保護を提供することにも、それを人々が最も機微な情報を保存するサービス全体のデフォルトにすることにも、繰り返しほとんど関心を示してきませんでした。
Big Tech のプライバシー保護では不十分です
Big Tech はユーザーのプライバシーをどのように扱っているのでしょうか。これらの企業がより強力な保護を提供する場合でも、それは部分的で、任意で、元に戻しやすいことが少なくありません。以下に例を挙げます。
- Apple の Advanced Data Protection(ADP)機能 — バックアップ、写真、メモ、ファイルなど、より多くの iCloud データにエンドツーエンド暗号化を拡張する任意の機能 — は、デフォルトで有効になっていません。2025年2月、Apple は英国で ADP を削除しました。これは、暗号化された iCloud データへのより広いアクセスを求める政府の圧力を受けたためです。Apple はその後この命令に異議を申し立てましたが、まず先にその保護を撤回していました。
- Meta は Instagram の会話に対するエンドツーエンド暗号化を任意機能として、しかも一部地域でしか提供していません。同社は最近、Instagram の DM から E2EE を完全に削除すると発表し、その理由として「ごく少数の人」しか利用していなかったと述べました。しかし、設定の奥深くに埋もれ、デフォルトで有効になっていないプライバシーツールは、ほとんどの人に見落とされがちです。
- Google はプライバシー侵害とは無縁ではなく、2025年だけで42億4,000万ドルの制裁金に直面しています。2026年1月、同社は、誤作動による起動後に Google Assistant がプライベートな会話を不適切に録音し、その録音がターゲット広告に使われたとユーザーが主張した訴訟を解決するため、6,800万ドルの支払いに同意しました(新しいウィンドウ)。
- AI は Big Tech のデータ収集モデルをさらに洗練させただけで、これらのプラットフォームは、モデルの改善、広告のパーソナライズ、より完全なユーザープロファイルの構築のために、機微な情報を大規模に収集・分析できるようになりました。たとえば Meta は、プライベートな会話の中であっても、Meta AI とのやり取りをすべて広告のために処理しています。一方 Google は、Gmail や Android を含むあらゆる場所に Gemini を追加しています。
政府はお客様のデータを購入することも、別ルートで要請することもできます
Big Tech への要請は全体像の一部にすぎません。FBI 長官のカシュ・パテル氏によれば、米当局は人々を追跡するためにデータブローカーから位置データを購入しています。これは、個人データが一見プライベートな収集から国家監視へと、いかに速く移り得るかを示しています。
長年にわたり、Big Tech は、利便性、パーソナライズ、そしてより良いインターネット体験には、プライバシーとの引き換えにする価値があるという考えをユーザーに信じ込ませてきました。実際にその取引が生み出したのは、個人データが資産として扱われる仕組みです。つまり、大規模に収集され、何年にもわたって保管され、購入できる者や法的に要求できる者なら誰でも利用できるようにされるのです。
親は、すでにこの仕組みが自分たちの子どもたちのために機能していないことを知っています
子どもの最初のデジタル上の痕跡は、多くの場合、できるだけ長くデータを収集、保持、分析するよう設計されたプラットフォームの中で生まれます。学校のアカウント、最初の受信トレイ、メッセージングアプリ、あるいはゲームのログインとして始まったものが、時間とともに、はるかに大きなプロフィールの土台になることがあります。ひとたびそのプロフィールが存在し、閲覧可能になると、AI システム、広告、データブローカー、政府など、ユーザーデータに関心を持つあらゆる主体にとって有用なものになります。ユーザーの年齢は関係ありません。
親はそのことを知っています。

米国の親を対象にした Proton の調査では、次のことがわかりました。
- 子どものオンラインプライバシーについて 78% が懸念しており、そのうち 56% は非常に強い懸念を抱いています。
- 子どものオンライン上の情報が身の安全に影響する可能性があると 70% が回答しました。
- 59% が評判への悪影響を懸念しています。
- 56% が将来の進学の見通しを懸念しています。
- 55% が将来の就職機会を懸念しています。
- 62% は、可能であれば子どものオンライン履歴をすべて消去して、最初からやり直したいと回答しました。
- 65% は、Big Tech が自分の子どもの個人データから利益を得ていると考えています。
子どもの情報がさらされるリスクを最初から減らす方法
どの親でも、子どもをデジタルの世界から完全に切り離しておくことはできません。しかし、そもそもその仕組みに入り込む個人データの量は、家庭で減らすことができます。
- 広告のために受信トレイをスキャンせず、閲覧可能なメッセージ内容を保持しないプライベートメールアドレスなど、デフォルトでプライベートなサービスから始めましょう。
- 不要なアカウント作成は遅らせましょう。多くのプラットフォームは、必要になる前から子どもにサインアップを促すからです。広告主導のエコシステム内で作成されるアカウントが少ないほど、存在するデータも少なくなります。
- 学校やアプリのデフォルト設定は、アプリの権限やプライバシー設定も含めて慎重に確認しましょう。教育プラットフォーム、教室向けツール、親と教師の連絡用メッセージアプリは、家族が想定する以上のデータを収集している場合があります。
- 早い段階で共有する情報は少なめにしましょう。写真、位置、行動履歴、そのほかの細かな詳細は、時間とともに積み重なって、はるかに大きなプロフィールになり得ます。
- 後付けではなく、設計段階から暗号化を選びましょう。設定の奥に埋もれた任意のプライバシー機能は見落としやすく、企業によって簡単に元に戻されることもあります。保護は、最初から組み込まれているときに最も効果を発揮します。
- プライバシー・バイ・デザインを意識して選びましょう。Big Tech 企業は、多くの人が最も簡単な選択肢をそのまま使い続けることを当て込んでいます。たとえそのデフォルトが、プライバシーよりもデータ収集を優先していてもです。
次の世代がこの欠陥のある仕組みを受け継ぐ必要はありません
現在の世代は、できるだけ多くの個人データを収集し保持するよう作られたプラットフォームの中で、すでに何年も過ごしてきました。現実的な代替手段はほとんどなく、今日の選択が明日のリスクを生み出し得ることへの理解もほとんどありませんでした。子どもたちは、同じ出発点に立たされるべきではありません。そして、デジタル生活の多くはメールアドレスから始まるからこそ、その最初の受信トレイが、その後のあらゆるものがどれだけプライベートになるか、あるいはどれだけさらされるかを左右し得るのです。
Big Tech が読み取り可能な形で保持するユーザー情報が多いほど、政府が要求できるデータ、AI システムが分析できるデータ、データブローカーが流通させられるデータも増えます。プライバシーは、単なるポリシーではなく、設計の問題です。異なる未来を望むなら、子どもたちが最初からこの仕組みを生み出したシステムの外にいられるようにしなければなりません。






