
Сегодня дети растут в системах, созданных для сбора и хранения их данных с самого первого момента, когда они выходят в онлайн. То, что начинается со школьного аккаунта, первого адреса электронной почты или приложения для обмена сообщениями, может превратиться в долговременную запись об их поведении, отношениях и идентичности. И эти данные могут оставаться доступными годами.
Новое исследование Proton показывает последствия этой системы в широком масштабе. За последнее десятилетие Google, Apple и Meta передали властям США данные более чем 3,5 миллиона аккаунтов пользователей — это рост на 770 % с тех пор, как компании начали сообщать о таких запросах. Если добавить к этому раскрытия данных в рамках Закона о надзоре за внешней разведкой (FISA), общее число возрастает до 6,9 миллиона.
Вот в чем реальная опасность того, что Big Tech определяет архитектуру детства онлайн. Данные, собираемые в коммерческих целях — для таргетинга рекламы, обучения ИИ и построения профилей, — позже могут оказаться под государственным надзором. Если этой системе позволят укорениться еще сильнее, следующему поколению достанется интернет, в котором конфиденциальность не просто постепенно ослабляют, а исключают из самой архитектуры с самого начала.
- Что показывает исследование о партнерстве Big Tech с властями
- Это возможно только потому, что Big Tech хранит ваши данные в читаемом виде
- Родители уже понимают, что эта система подводит их детей
- Как с самого начала снизить степень раскрытия данных вашего ребенка
- Следующему поколению не должна достаться эта несовершенная система
Что показывает исследование о партнерстве Big Tech с властями
Наш анализ за 2025 год показал, что за предыдущее десятилетие доступ государственных органов к данным пользователей, хранящимся у Big Tech, резко вырос. Последние отчеты о прозрачности показывают, что эта тенденция сохраняется.
Власти США по-прежнему полагаются на Big Tech как на источник данных пользователей
С конца 2014 года до начала 2025 года Google, Meta и Apple передали властям США данные более чем 3,5 миллиона аккаунтов пользователей в ответ на стандартные запросы.
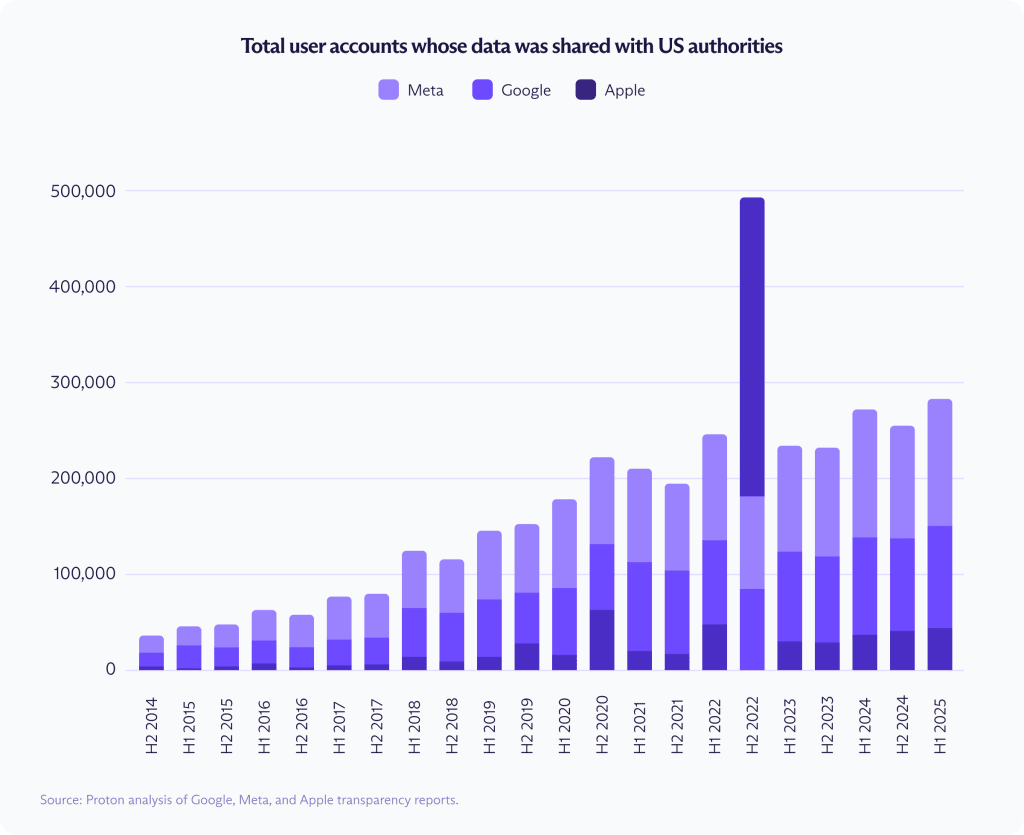
За этот период число аккаунтов, данные которых были раскрыты, выросло на 557 % у Google, на 668 % у Meta и на 927 % у Apple. Только в первой половине 2025 года эти компании раскрыли данные более чем 282 000 американских аккаунтов.

Показатель в 3,5 миллиона отражает обычные государственные запросы, о которых сообщается в стандартных отчетах о прозрачности. Он не включает запросы, сделанные в рамках Закона о надзоре за внешней разведкой (FISA), которые сообщаются отдельно по правилам национальной безопасности и с меньшим количеством подробностей. Если включить запросы FISA на предоставление содержимого, общее число случаев раскрытия данных аккаунтов к концу 2024 года вырастает примерно до 6,7 миллиона.

С 2014 по 2024 год число заявленных запросов FISA на предоставление содержимого выросло на 2 486 % у Meta и на 649 % у Google. Apple не публикует сопоставимые данные, уходящие к 2014 году, но число раскрытых запросов FISA на предоставление содержимого у компании выросло на 443 % в период с 2018 по 2024 год. Отсечкой выбран 2024 год, потому что отчетность по FISA, в отличие от обычных данных о прозрачности, пока не охватывает 2025 год.
Число запросов из ЕС резко растет
Европейские правительства не сопоставимы с США по общему объему, но число запросов по всему Европейскому союзу продолжает быстро расти.
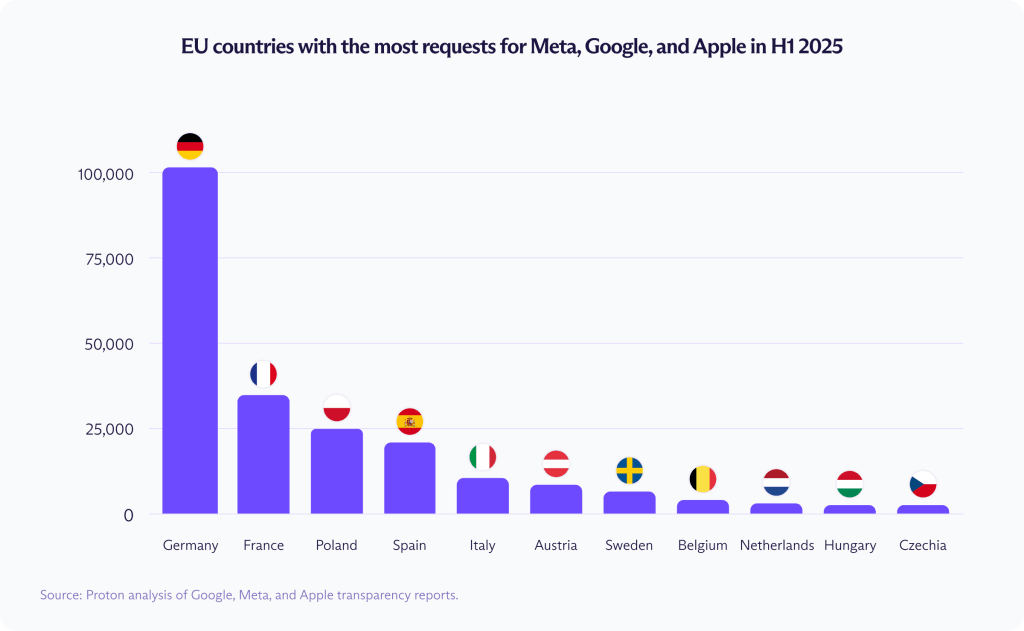
В первой половине 2025 года государства — члены ЕС запросили данные по 231 199 аккаунтам пользователей против 164 472 за тот же период годом ранее — рост составил примерно 40 %. С конца 2014 года общее число запросов выросло более чем на 1 100 %.
Рост распределяется неравномерно. Наибольшая доля в первой половине 2025 года пришлась на Германию, которая запросила данные по 101 811 аккаунтам пользователей, за ней следуют Франция (36 831), Польша (24 373) и Испания (20 984).
Это возможно только потому, что Big Tech хранит ваши данные в читаемом виде
Проблема не в том, что компании выполняют законные запросы властей: любая компания, которая хочет продолжать работать в стране, должна исполнять ее действительные правовые предписания. Более глубокая проблема в том, что Google, Meta и Apple построили свои системы вокруг сбора и хранения огромных объемов личных данных в форме, к которой сами могут получить доступ. Если компания хранит ключи, она может читать ваши данные. А если она может читать ваши данные, ее можно обязать передать их.
Сквозное шифрование — самый надежный способ ограничить объем данных, которые можно раскрыть, потому что компания не может передать то, что не способна расшифровать. В лучшем случае она может выдать зашифрованные материалы, которые на практике невозможно прочитать. Но компании Big Tech не раз демонстрировали слабую заинтересованность в предоставлении такой защиты, не говоря уже о том, чтобы делать ее настройкой по умолчанию во всех сервисах, где люди хранят самую чувствительную информацию.
Меры Big Tech по защите конфиденциальности недостаточны
Как Big Tech обращается с конфиденциальностью пользователей? Даже когда эти компании предлагают более надежную защиту, она часто бывает частичной, необязательной или легко обратимой. Вот несколько примеров:
- Apple Advanced Data Protection (ADP) — необязательная функция, которая распространяет сквозное шифрование на больший объем данных iCloud, включая резервные копии, фото, заметки и файлы, — не включена по умолчанию. В феврале 2025 года Apple отключила ADP в Великобритании после давления со стороны властей, добивавшихся большего доступа к зашифрованным данным iCloud. Позже Apple оспорила это распоряжение, но только после того, как сначала отменила эту защиту.
- Meta предлагает сквозное шифрование для переписки в Instagram только как необязательную функцию и только в некоторых регионах. Недавно компания объявила, что полностью удалит E2EE из личных сообщений Instagram, заявив, что им пользовалось «очень мало людей». Но большинство людей просто не замечают инструменты защиты конфиденциальности, если они глубоко спрятаны в настройках и не включены по умолчанию.
- Google не чужды нарушения конфиденциальности: только в 2025 году компания столкнулась со штрафами на сумму 4,24 млрд долларов. В январе 2026 года компания согласилась выплатить 68 млн долларов(новое окно), чтобы урегулировать иск, в котором утверждалось, что Google Assistant ненадлежащим образом записывал конфиденциальные разговоры после ложных срабатываний, а пользователи заявляли, что эти записи затем использовались для таргетированной рекламы.
- ИИ лишь довел до совершенства модель Big Tech по массовому сбору данных, позволив этим платформам в большом масштабе собирать и анализировать конфиденциальную информацию — будь то для улучшения моделей, персонализации рекламы или создания более полных профилей пользователей. Например, Meta обрабатывает все взаимодействия с Meta AI для рекламы, даже внутри конфиденциальных переписок, а Google добавила Gemini повсюду, включая Gmail и Android.
Власти могут купить ваши данные или запросить их в другом месте
Запросы к Big Tech — лишь часть общей картины. По словам директора ФБР Кэша Пателя, власти США покупают данные о местоположении у брокеров данных, чтобы отслеживать людей, и это показывает, как быстро личные данные могут перейти из сферы, где их сбор кажется конфиденциальным, в сферу государственного надзора.
Годами Big Tech внушал пользователям, что удобство, персонализация и более комфортная работа в интернете стоят того, чтобы поступиться конфиденциальностью. На деле эта сделка создала систему, в которой персональные данные рассматриваются как актив: их массово собирают, годами хранят и делают доступными для любого, кто может их купить или законно потребовать.
Родители уже знают, что эта система подводит их детей
Первые цифровые следы ребенка часто появляются внутри платформ, созданных для того, чтобы как можно дольше собирать, хранить и анализировать данные. То, что начинается со школьного аккаунта, первого почтового ящика, приложения для обмена сообщениями или имени пользователя для игры, со временем может стать основой гораздо более обширного профиля. Как только такой профиль появляется и остается доступным для прочтения, он становится полезным для всех, кто заинтересован в данных пользователей, включая системы ИИ, рекламу, брокеров данных и правительства — независимо от возраста пользователя.
Родители это знают.

Опрос Proton среди родителей в США показал, что:
- 78% обеспокоены конфиденциальностью ребенка в интернете, в том числе 56% — очень обеспокоены.
- 70% заявили, что размещенная в интернете информация об их ребенке может повлиять на его личную безопасность.
- 59% обеспокоены ущербом для репутации.
- 56% обеспокоены перспективами в образовании.
- 55% обеспокоены будущими возможностями трудоустройства.
- 62% сказали, что стерли бы всю онлайн-историю своего ребенка и начали с чистого листа, если бы могли.
- 65% считают, что Big Tech зарабатывает на персональных данных их ребенка.
Как с самого начала уменьшить цифровую уязвимость вашего ребенка
Ни один родитель не может полностью оградить ребенка от цифрового мира. Но семьи могут сократить объем персональных данных, которые вообще попадают в систему.
- Начните с сервисов с конфиденциальностью по умолчанию, включая конфиденциальный адрес электронной почты, где почтовый ящик не сканируется ради рекламы, а содержимое сообщений не хранится в читаемом виде.
- Не спешите создавать ненужные аккаунты, поскольку многие платформы подталкивают детей зарегистрироваться раньше, чем это действительно нужно. Чем меньше аккаунтов создается в рекламных экосистемах, тем меньше данных в них попадает.
- Внимательно проверяйте школьные настройки и настройки приложений по умолчанию, включая разрешения приложений и настройки конфиденциальности. Образовательные платформы, инструменты для занятий и приложения для общения родителей с учителями могут собирать больше данных, чем ожидают семьи.
- С самого начала делитесь как можно меньшим количеством информации, включая фотографии, местоположение, историю активности и другие мелкие детали, которые со временем могут сложиться в гораздо более обширный профиль.
- Выбирайте шифрование, встроенное в сервис изначально, а не добавленное задним числом. Дополнительные функции конфиденциальности, спрятанные в настройках, легко упустить из виду, и компаниям легко их отменить. Защита особенно важна, когда она встроена с самого начала.
- Осознанно выбирайте конфиденциальность, заложенную в архитектуру сервиса, потому что компании Big Tech рассчитывают, что большинство людей останутся с самым простым вариантом, даже если эти настройки по умолчанию отдают приоритет сбору данных, а не конфиденциальности.
Следующее поколение не должно унаследовать эту несовершенную систему
Нынешнее поколение уже провело годы внутри платформ, созданных для сбора и хранения как можно большего объема персональных данных; реальных альтернатив почти не было, и мало кто понимал, как сегодняшние решения могут создать завтрашние риски. Дети не должны начинать с той же точки. И поскольку значительная часть цифровой жизни начинается с адреса электронной почты, первый почтовый ящик может определить, насколько конфиденциальным (или открытым) будет всё, что последует дальше.
Чем больше информации о пользователях Big Tech хранит в читаемом виде, тем больше данных правительства могут запрашивать, системы ИИ — анализировать, а брокеры данных — распространять. Конфиденциальность — это вопрос архитектуры, а не только политики. Если мы хотим другого будущего, детям нужно начинать вне систем, которые создали нынешнюю.






