
Dzieci dorastają dziś w systemach zaprojektowanych do gromadzenia i zachowywania ich danych od pierwszego momentu, w którym wejdą online. To, co zaczyna się jako konto szkolne, pierwszy adres e-mail lub aplikacja do przesyłania wiadomości, może stać się długoterminowym zapisem ich zachowań, relacji i tożsamości. Dane te mogą pozostać dostępne przez lata.
Nowe badania od Proton pokazują konsekwencje tego systemu na dużą skalę. W ciągu ostatniej dekady firmy Google, Apple i Meta udostępniły władzom USA dane z ponad 3,5 miliona kont użytkowników — to wzrost o 770% odkąd firmy te zaczęły raportować takie zapytania. W połączeniu z ujawnieniami na mocy ustawy o nadzorze wywiadu zagranicznego (FISA), liczba ta rośnie do 6,9 miliona.
To prawdziwe niebezpieczeństwo pozwolenia firmom Big Tech na zdefiniowanie architektury dzieciństwa online. Dane gromadzone w celach komercyjnych — do kierowania reklam, trenowania sztucznej inteligencji i budowania profili — mogą być później narażone na inwigilację państwową. Jeśli ten system będzie się pogłębiać, następne pokolenie odziedziczy internet, w którym prywatność nie jest stopniowo osłabiana, lecz usuwana już na etapie projektowania.
- Co badania pokazują o partnerstwach Big Tech z rządem
- Jest to możliwe tylko dlatego, że Big Tech utrzymuje Twoje dane możliwe do przeczytania
- Rodzice już wiedzą, że system zawodzi ich dzieci
- Jak od samego początku ograniczyć narażenie dziecka na ryzyko
- Kolejne pokolenie nie musi dziedziczyć tego wadliwego systemu
Co badania pokazują o partnerstwach Big Tech z rządem
Nasza analiza z 2025 roku wykazała, że dostęp rządu do danych użytkowników posiadanych przez Big Tech gwałtownie wzrósł w ciągu poprzedniej dekady. Najnowsze raporty przejrzystości pokazują, że ten trend się utrzymuje.
Władze USA wciąż polegają na Big Tech w kwestii danych użytkowników
Między końcem 2014 a początkiem 2025 roku, firmy Google, Meta i Apple udostępniły władzom USA dane z ponad 3,5 miliona kont użytkowników w odpowiedzi na rutynowe zapytania.
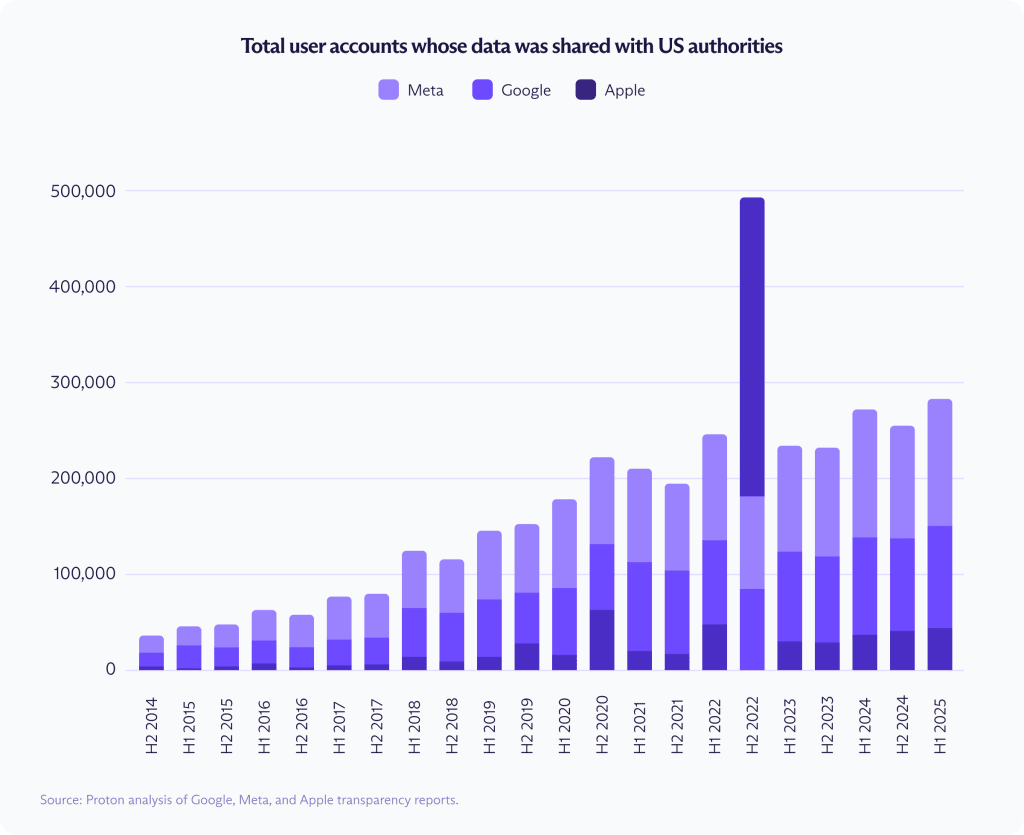
W tym okresie liczba ujawnionych kont wzrosła o 557% w Google, 668% w firmie Meta i 927% w Apple. Tylko w pierwszej połowie 2025 roku firmy te ujawniły dane z ponad 282 000 amerykańskich kont.

Liczba 3,5 miliona odzwierciedla rutynowe wnioski rządowe raportowane w ramach standardowych ujawnień dotyczących przejrzystości. Nie obejmuje ona wniosków złożonych na mocy ustawy o nadzorze wywiadu zagranicznego (FISA), które są raportowane osobno zgodnie z przepisami o bezpieczeństwie narodowym i z mniejszą ilością szczegółów. Jeśli włączymy zapytania o treści z FISA, całkowita liczba ujawnień do końca 2024 roku wzrasta do około 6,7 miliona.

W latach 2014-2024 zgłoszone wnioski o zawartość z FISA wzrosły o 2486% w firmie Meta i 649% w Google. Firma Apple nie publikuje porównywalnych danych z 2014 r., ale ujawnione przez nią wnioski o udostępnienie zawartości z FISA wzrosły o 443% między 2018 a 2024 r. Punktem odcięcia jest rok 2024, ponieważ raportowanie FISA nie obejmuje jeszcze roku 2025, w przeciwieństwie do rutynowych danych dotyczących przejrzystości.
Liczba wniosków z UE gwałtownie rośnie
Rządy państw europejskich nie dorównują USA pod względem całkowitej liczby zapytań, ale wnioski w całej Unii Europejskiej wciąż szybko rosną.
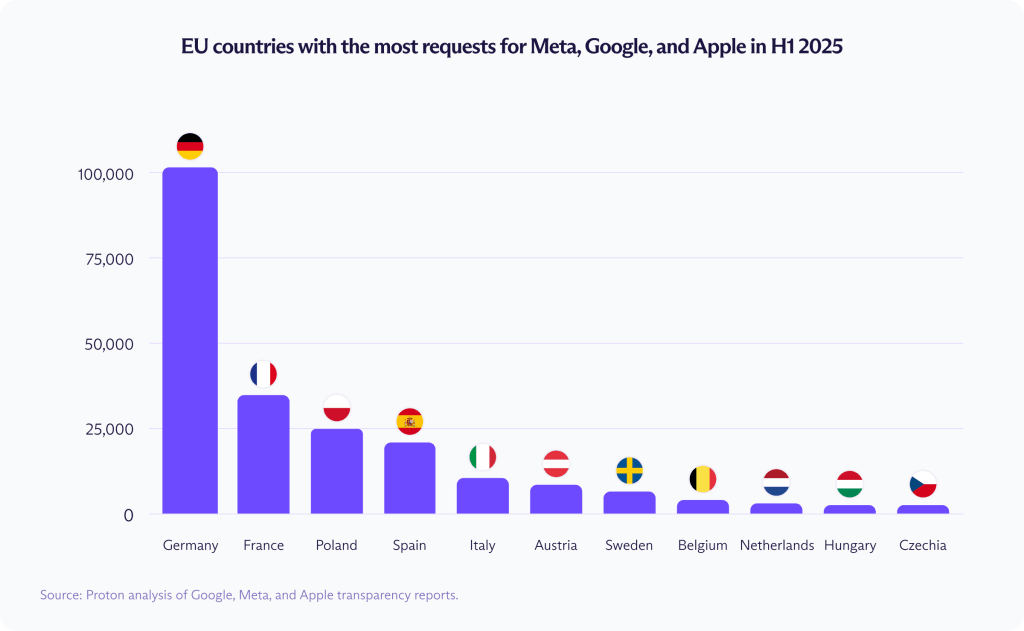
W pierwszej połowie 2025 r. państwa członkowskie UE zażądały danych dotyczących 231 199 kont użytkowników, co stanowi wzrost ze 164 472 w tym samym okresie rok wcześniej — to wzrost o około 40%. Od końca 2014 roku łączna liczba wniosków wzrosła o ponad 1100%.
Wzrost nie jest rozłożony równomiernie. Największy udział w pierwszej połowie 2025 r. miały Niemcy, żądając danych na temat 101 811 kont użytkowników, a w dalszej kolejności Francja (36 831), Polska (24 373) i Hiszpania (20 984).
Jest to możliwe tylko dlatego, że Big Tech utrzymuje Twoje dane w formie możliwej do odczytania
Problem nie leży w tym, że firmy stosują się do zgodnych z prawem żądań rządowych, ponieważ każda firma, która chce kontynuować działalność w danym kraju, musi odpowiadać na jego ważne nakazy prawne. Głębszym problemem jest to, że firmy Google, Meta i Apple zbudowały systemy wokół gromadzenia i zachowywania ogromnych ilości danych osobowych w formach, do których wciąż mają dostęp. Jeśli firma ma klucze, może przeczytać Twoje dane. A jeśli może je przeczytać, to może zostać zmuszona do ich przekazania.
Szyfrowanie end-to-end to najpewniejszy sposób na ograniczenie tego, co może zostać ujawnione, ponieważ firma nie może przekazać czegoś, czego nie może odszyfrować. Co najwyżej może oddać zaszyfrowane materiały, których nie da się skutecznie odczytać. Jednak firmy Big Tech wielokrotnie wykazywały niewielkie zainteresowanie oferowaniem tego rodzaju ochrony, a tym bardziej czynieniem z niej domyślnego standardu w usługach, w których ludzie przechowują swoje najbardziej wrażliwe informacje.
Zabezpieczenia prywatności Big Tech nie są wystarczające
Jak Big Tech podchodzi do prywatności użytkowników? Gdy firmy te oferują silniejsze zabezpieczenia, są one często częściowe, opcjonalne lub łatwe do odwrócenia. Oto kilka przykładów:
- Funkcja zaawansowanej ochrony danych (ADP) od Apple — opcjonalna funkcja, która rozszerza szyfrowanie end-to-end na większą liczbę danych w iCloud, w tym kopie zapasowe, zdjęcia, notatki i pliki — nie jest włączona domyślnie. W lutym 2025 r. firma Apple usunęła ADP w Wielkiej Brytanii po naciskach rządu na zwiększenie dostępu do zaszyfrowanych danych w iCloud. Później firma Apple zakwestionowała to zarządzenie, ale dopiero po wcześniejszym wycofaniu ochrony.
- Meta oferuje szyfrowanie end-to-end dla konwersacji na Instagramie tylko jako opcjonalną funkcję i tylko w wybranych regionach. Firma niedawno ogłosiła, że całkowicie usunie E2EE z wiadomości na Instagramie, twierdząc, że korzysta z niego „bardzo niewiele osób”. Jednak narzędzia prywatności, które są ukryte głęboko w ustawieniach i nie są domyślnie włączone, mogą być z łatwością przeoczone przez większość osób.
- Firmie Google nie są obce naruszenia prywatności, z karami w wysokości 4,24 miliarda dolarów tylko w 2025 r.. W styczniu 2026 r. firma zgodziła się zapłacić 68 milionów dolarów(nowe okno) w ramach ugody w sprawie oskarżeń o to, że Asystent Google niewłaściwie nagrywał prywatne rozmowy po fałszywych aktywacjach, a użytkownicy twierdzili, że nagrania te były następnie używane do ukierunkowanych reklam.
- Sztuczna inteligencja tylko udoskonaliła model gromadzenia danych Big Tech, pozwalając tym platformom na zbieranie i analizowanie poufnych informacji na wielką skalę — niezależnie od tego, czy chodzi o ulepszanie modeli, personalizację reklam, czy budowanie pełniejszych profili użytkowników. Na przykład firma Meta przetwarza wszystkie interakcje ze swoją sztuczną inteligencją w celach reklamowych, nawet w prywatnych wątkach, podczas gdy Google dodało Gemini wszędzie, w tym do Gmaila oraz systemu Android.
Rządy mogą kupić Twoje dane lub zażądać ich w innym miejscu
Zapytania do Big Tech to tylko część obrazu. Według dyrektora FBI Kasha Patela, władze USA kupują dane o lokalizacji od brokerów danych, aby śledzić ludzi, co pokazuje, jak szybko dane osobowe mogą przejść z pozornie prywatnego zbioru do państwowej inwigilacji.
Przez lata giganci technologiczni wmawiali użytkownikom, że wygoda, personalizacja i lepsze wrażenia z korzystania z internetu są warte kompromisów w kwestii prywatności. W rzeczywistości ta transakcja stworzyła system, w którym dane osobowe są traktowane jako zasób: zbierane na masową skalę, przechowywane przez lata i udostępniane każdemu, kto może je kupić lub legalnie ich zażądać.
Nadrzędni opiekunowie już wiedzą, że system zawodzi ich dzieci
Pierwsze cyfrowe ślady dziecka są często tworzone wewnątrz platform zaprojektowanych tak, aby gromadzić, przechowywać i analizować logi oraz dane tak długo, jak to możliwe. To, co zaczyna się jako szkolne konto, pierwsza skrzynka odbiorcza, aplikacja do przesyłania wiadomości lub opcja zaloguj się w grze, z biegiem czasu może stać się fundamentem znacznie większego profilu. Gdy ten profil już istnieje i może zostać przeczytany, staje się użyteczny dla każdego, kto jest zainteresowany danymi użytkownika – w tym systemów sztucznej inteligencji, reklamodawców, brokerów danych czy rządów, niezależnie od wieku użytkownika.
Nadrzędni opiekunowie o tym wiedzą.

Badanie Proton wśród nadrzędnych rodziców z USA wykazało, że:
- 78% martwi się o prywatność swojego dziecka online, w tym 56% jest bardzo zaniepokojonych.
- 70% stwierdziło, że informacje o ich dziecku online mogą wpłynąć na jego bezpieczeństwo osobiste.
- 59% obawia się utraty reputacji.
- 56% martwi się o perspektywy edukacyjne.
- 55% martwi się o przyszłe możliwości zatrudnienia.
- 62% stwierdziło, że gdyby mogło, usunęłoby całą historię online swojego dziecka i zaczęłoby wszystko od nowa.
- 65% uważa, że giganci technologiczni czerpią zyski z danych osobowych ich dziecka.
Jak od samego początku zmniejszyć narażenie dziecka
Żaden nadrzędny opiekun nie może utrzymać swojego dziecka całkowicie poza cyfrowym światem. Jednak rodziny mogą zmniejszyć ilość danych osobowych, które w ogóle wpiszesz do systemu.
- Zacznij od usług domyślnie prywatnych, w tym prywatnego adresu e-mail, który nie skanuje skrzynek odbiorczych w poszukiwaniu reklam ani nie przechowuje czytelnej treści wiadomości.
- Opóźnij niepotrzebne tworzenie kont, ponieważ wiele platform naciska na dzieci, aby zdecydowały się zarejestrować się wcześniej, niż to konieczne. Im mniej kont w ekosystemach napędzanych reklamami, tym mniej danych.
- Dokładnie przeglądaj wartości domyślne szkół i aplikacji, w tym uprawnienia aplikacji i ustawienia prywatności. Edukacyjne platformy, narzędzia klasowe i aplikacje komunikacyjne nadrzędnych i nauczycieli mogą zbierać więcej danych, niż rodziny by tego oczekiwały.
- Na początku staraj się udostępniać mniej, w tym zdjęcia, lokalizacje, historie aktywności i inne drobne szczegóły, które z czasem mogą składać się na znacznie większy profil.
- Wybieraj szyfrowanie w fazie projektowania, a nie jako dodatek. Opcjonalne funkcje prywatności ukryte w ustawieniach są łatwe do przeoczenia i łatwe do cofnięcia przez firmy. Zabezpieczenia liczą się najbardziej, gdy są wbudowane od samego początku.
- Bądź świadomy, celowo decydując się na prywatność, ponieważ giganci technologiczni liczą na to, że większość ludzi pozostanie przy tym, co najłatwiejsze, nawet jeśli te ustawienia domyślne faworyzują gromadzenie danych nad prywatność.
Kolejne pokolenie nie musi dziedziczyć tego wadliwego systemu
Obecna generacja spędziła już lata wewnątrz platform zbudowanych tak, aby gromadzić i przechowywać jak najwięcej danych osobowych; istniało niewiele prawdziwych alternatyw i mało było zrozumienia, w jaki sposób dzisiejsze wybory mogą stworzyć jutrzejsze zagrożenia. Dzieci nie powinny zaczynać w tym samym miejscu. A ponieważ tak duża część cyfrowego życia zaczyna się przez adres e-mail, ta pierwsza skrzynka odbiorcza może kształtować, jak bardzo prywatne (lub ujawnione) będzie wszystko, co nastąpi potem.
Im więcej informacji o użytkowniku Big Tech przechowuje jako przeczytane, tym więcej danych mogą żądać rządy, tym więcej mogą analizować systemy SI i tym więcej mogą przetwarzać brokerzy danych. Prywatność jest kwestią architektury, a nie tylko zasad. Jeśli chcemy innej przyszłości, musimy zaczynać z dziećmi poza systemami, które stworzyły tę obecną.






